За какво се използват търсачките? Търсачки. Как да използвате търсачката
Издадохме нова книга „Маркетинг на съдържанието в в социалните мрежи: Как да влезете в главите на вашите абонати и да ги накарате да се влюбят във вашата марка.
Как работи търсачката - основни принципи
Всеки повече или по-малко опитен интернет потребител може да намери необходимата информация с помощта на търсачка. Въпреки това, само няколко души знаят как работят търсачките. Наистина, как Google или Yandex успяват да анализират заявката на потребителя за няколко секунди и да изберат най-подходящите сайтове от милионите уеб проекти, присъстващи в Интернет?
За да разберете принципа на работа търсачки, трябва да се запознаете с концепции като индексиране и генериране на резултати. Всъщност ролята на търсачката се свежда до анализиране на съществуващи сайтове в мрежата и извеждане на информация, която най-добре отговаря на нуждите на интернет потребителя.
Още видеоклипове в нашия канал - научете интернет маркетинг със SEMANTICA
Как работи търсачката - индексиране на сайта
Има търсачки, които постоянно „ходят“ в интернет, посещавайки всички сайтове, които са им известни с определена честота. След като откри нов материал, роботът го добавя към своята индексна база данни в обикновен текст. Всяка търсачка има нещо като „картотека“, в която се съхраняват копия на индексирани уеб страници.
Ако роботът посети предварително индексирана страница, той сравнява съществуващото копие с текущото състояние на документа. Ако има значителни несъответствия (ако материалът е актуализиран), се правят промени в индексната база данни.
съвет! Колкото по-често се актуализира един сайт, толкова по-често роботите за търсене ще го посещават. Това ще има положителен ефект върху индексирането.
Генериране на подходящи резултати
Точните принципи на работа на търсачките се пазят строго поверителни. Освен това алгоритмите непрекъснато се подобряват и променят. Съвсем очевидно е обаче, че темата на документа се определя въз основа на анализа на неговата семантика. Търсачките могат да обърнат внимание на следните аспекти:
- честота на използване на ключови заявки;
- тематично съответствие на материала с основната тема на сайта;
- наличие на синоними за ключови фрази;
- наличие на ключове в заглавия, мета тагове и др.
Разбира се, търсачките вземат предвид не само качеството на текста, но и много други параметри. Важното е доверието на сайта, възрастта на домейна и състоянието на базата с връзки. IN напоследък голямо значениепридобити поведенчески фактори (активност на потребителя - брой прегледани страници, коментари и др.).
Как работят търсачките - отговорът на запитването
Въз основа на въведената заявка за търсене, системата анализира индексираните материали. След това роботът генерира връзки към сайтове, които най-добре отговарят на заявката на потребителя. Наскоро бяха направени някои промени в начина, по който работи търсачката. Сега роботите генерират резултати от търсенето, като вземат предвид предпочитанията на потребителите.
Нека обясним на конкретен пример: има двама потребители, единият от които се интересува кулинарни рецепти, а другата често си поръчва бърза храна вкъщи. Тези потребители могат да въведат една и съща заявка „вкусна пица“, но търсачката ще им предостави връзки към различни сайтове. Първият ще получи списък с рецепти за приготвяне на пица, а вторият ще получи адресите на ресторанти, специализирани в доставката на това ястие.
По дефиниция интернет търсачката е система за извличане на информация, която ни помага да намираме информация в световната мрежа. Това улеснява глобалния обмен на информация. Но Интернет е неструктурирана база данни. Той се разраства експоненциално и се превърна в огромно хранилище на информация. Намирането на информация в интернет е трудна задача. Има нужда от инструмент за управление, филтриране и извличане на тази океанска информация. Търсачката служи за тази цел.
Как работи търсачката?
Интернет търсачките са машини, които търсят и извличат информация в Интернет. Повечето от тях използват архитектура на индексатор за обхождане. Те зависят от техните коловозни модули. Пълзящите се наричат още паяци малки програмикоито сърфират в мрежата.
Роботите посещават първоначален набор от URL адреси. Те копаят URL адреси, които се появяват на обходените страници, и изпращат тази информация до модула за контрол на робота. Роботът решава кои страници да посети следващите и дава тези URL адреси на роботите.
Темите, обхванати от различните търсачки, варират в зависимост от алгоритмите, които използват. Някои търсачки са програмирани да търсят сайтове по конкретна тема, докато роботите на други могат да посетят възможно най-много места.
Модулът за индексиране извлича информация от всяка страница, която посещава, и въвежда URL адреса в базата данни. Това води до огромна справочна таблица със списък от URL адреси, сочещи към страници с информация. Таблицата показва страниците, които са били обхванати по време на обхождането.
Модулът за анализ е друга важна част от архитектурата на търсачката. Той създава индекс на полезност. Помощната програма за индексиране може да осигури достъп до страници с определена дължина или страници, съдържащи определен брой снимки върху тях.
По време на процеса на обхождане и индексиране, търсачката съхранява страниците, които извлича. Те се съхраняват временно в хранилището на страницата. Търсачките поддържат кеш на страниците, които посещават, за да ускорят извличането на страници, които вече са били посетени.
Модулът за заявки на търсачката получава заявки за търсене от потребители под формата на ключови думи. Модулът за класиране сортира резултатите.
Архитектурата на индексатора за обхождане има много вариации. Те се променят в разпределената архитектура на търсачката. Тези архитектури се състоят от колекционери и брокери. Колекционерите събират информация за индексиране от уеб сървъри, докато брокерите осигуряват машината за индексиране и интерфейса за заявки. Брокерите индексират актуализацията въз основа на информация, получена от колекционери и други брокери. Те могат да филтрират информация. Много търсачки днес използват този тип архитектура.
Търсачки и класиране на страници
Когато създаваме заявка в търсачката, резултатите се показват в определен ред. Повечето от нас са склонни да посещават най-горните страници и да игнорират долните. Това е така, защото вярваме, че първите няколко страници са по-подходящи за нашата заявка. Така че всеки се интересува от класирането на страниците му в първите десет резултата от търсачките.
Думите, изброени в интерфейса за заявки на търсачката, са ключови думи, които бяха заявени в търсачките. Те представляват списък от страници, свързани с търсените ключови думи. По време на този процес търсачките извличат онези страници, които често срещат тези ключови думи. Те търсят връзки между ключови думи. Поставянето на ключови думи също има значение, както и класирането на страниците, които ги съдържат. Ключовите думи, които се появяват в заглавията на страниците или URL адресите, получават по-голяма тежест. Страници, които имат връзки, сочещи към тях, ги правят още по-популярни. Ако много други сайтове се свързват към страница, тя се възприема като ценна и по-подходяща.
Има алгоритъм за класиране, който използва всяка търсачка. Алгоритъмът е компютъризирана формула, предназначена да предостави подходящи страници за заявката на потребителя. Всяка търсачка може да има различен алгоритъм за класиране, който анализира страници в базата данни на машината, за да определи съответните отговори на заявките за търсене. Търсачките индексират различна информация по различен начин. Това означава, че дадена заявка, отправена към две различни търсачки, може да върне страници в различен ред или да извлече различни страници. Популярността на един уебсайт са фактори, които определят уместността. Популярността при кликване на даден сайт е друг фактор, който определя неговия ранг. Това е мярка за това колко често се посещава даден сайт.
Уеб администраторите се опитват да измамят алгоритмите на търсачките, за да повишат класирането на своя сайт в резултатите от търсенето. Пълнене на страници на уебсайтове с ключови думи или използване на мета тагове за измама на стратегиите за класиране в търсачките. Но търсачките са достатъчно умни! Те подобряват своите алгоритми, така че машинациите на уеб администраторите да не влияят на резултатите от търсенето.
Трябва да разберете, че дори страниците след първите няколко в списъка може да съдържат точно информацията, която търсите. Но бъдете сигурни, че добрите търсачки винаги ще ви предоставят изключително подходящи страници в най-горния ред!
Здравейте, скъпи читатели!
В момента в глобалното интернет пространство има доста търсачки. Всяка от тях има свои собствени алгоритми за индексиране и класиране на сайтове, но като цяло принципът на търсачките е доста сходен.
Познаването на това как работи търсачката в условията на бързо нарастваща конкуренция е значително предимство при популяризирането не само на търговски, но и на информационни сайтове и блогове. Това знание ви помага да изградите ефективна стратегия за оптимизиране на уебсайта и с по-малко усилия да стигнете до ТОП на резултатите от търсенето за популяризирани групи заявки.
Как работят търсачките
Целта на работата на оптимизатора е да „настрои“ рекламираните страници към алгоритмите за търсене и по този начин да помогне на тези страници да постигнат високи позиции за определени заявки. Но преди да започнете работа по оптимизиране на уебсайт или блог, е необходимо поне повърхностно да разберете особеностите на работата на търсачките, за да разберете как те могат да реагират на действията, предприети от оптимизатора.
Разбира се, подробните подробности за формирането на резултатите от търсенето са информация, която търсачките не разкриват. Въпреки това, за правилното търсене е достатъчно разбирането на основните принципи, по които работят търсачките.
Методи за търсене на информация
Два основни метода, използвани днес търсачки, се различават по подхода си към търсенето на информация.
- Алгоритъм директно търсене , което включва съпоставяне на всеки от документите, съхранявани в базата данни на търсачката с ключова фраза (потребителска заявка), е доста надежден метод, който ви позволява да намерите всички необходимата информация. Недостатъкът на този метод е, че при търсене на големи масиви от данни времето, необходимо за намиране на отговора, е доста дълго.
- Алгоритъм за обратен индекс, когато ключова фраза е свързана със списък от документи, в които присъства, е удобно при взаимодействие с бази данни, съдържащи десетки и стотици милиони страници. При този подход търсенето не се извършва във всички документи, а само в специални файлове, включително списъци с думи, съдържащи се на страниците на уебсайта. Всяка дума в такъв списък е придружена от указание за координатите на позициите, където се среща, и други параметри. Именно този метод се използва днес в работата на такива известни търсачки като Yandex и Google.
Тук трябва да се отбележи, че когато потребител влезе в лентата за търсене на браузъра, търсенето се извършва не директно в Интернет, а в предварително събрани, запазени и текущи бази данни, съдържащи блокове от информация, обработвана от търсачките (страници на уебсайтове) . Бързото генериране на резултати от търсенето е възможно благодарение на работата с обратни индекси.

Текстовото съдържание на страниците (директни индекси) също се запазва от търсачките и се използва за автоматично генериране на фрагменти от текстовите фрагменти, които са най-подходящи за заявката.
Математически модел за класиране
За да се ускори търсенето и да се опрости процеса на генериране на резултати, които най-добре отговарят на заявката на потребителя, се използва определен математически модел. Задачата на този математически модел е да намери необходимите страници в текущата база данни с обратни индекси, да оцени степента им на съответствие с искането и да ги разпредели в низходящ ред на релевантност.
Просто намирането на желаната фраза на страницата не е достатъчно. Когато се определя от търсачките, теглото на документа се изчислява спрямо заявката на потребителя. За всяка заявка този параметър се изчислява въз основа на следните данни: честота на използване на анализираната страница и коефициент, отразяващ колко рядко същата дума се появява в други документи в базата данни на търсачката. Произведението на тези две количества съответства на теглото на документа.
Разбира се, представеният алгоритъм е много опростен, тъй като е на наше разположение търсачкиима редица други допълнителни коефициенти, използвани в изчисленията, но значението не се променя. Колкото по-често отделна думаот искането на потребителя се среща във всеки документ, толкова по-голяма е тежестта на последния. В този случай текстовото съдържание на страницата се счита за спам, ако са превишени определени ограничения, които са различни за всяка заявка.
Основни функции на търсачката
Всички съществуващи системи за търсене са проектирани да извършват няколко важни функции: търсене на информация, индексирането й, качествена оценка, правилно класиране и генериране на резултати от търсенето. Основната задача на всяка търсачка е да предостави на потребителя информацията, която търси, и най-точния отговор на конкретно запитване.
Тъй като повечето потребители нямат представа как работят интернет търсачките и възможността да се обучават потребителите как да търсят „правилно“ е много ограничена (например със съвети за търсене), разработчиците са принудени да подобрят самото търсене. Последното включва създаването на алгоритми и принципи на работа на търсачките, които позволяват да се намери необходимата информация, независимо от това колко „правилно“ е формулирана заявката за търсене.
Сканиране
Това е проследяване на промени във вече индексирани документи и търсене на нови страници, които могат да бъдат представени в резултатите от търсенето за потребителски заявки. Търсачките сканират ресурсите в интернет с помощта на специализирани програминаречени паяци или роботи за търсене.
Сканирането на интернет ресурси и събирането на данни се извършва автоматично от ботове за търсене. След първото посещение на даден сайт и включването му в базата данни за търсене, роботи започват периодично да посещават този сайт, за да наблюдават и записват промените, настъпили в съдържанието.
Тъй като броят на развиващите се ресурси в Интернет е голям и всеки ден се появяват нови сайтове, описаният процес не спира нито за минута. Този принцип на работа на търсачките в интернет им позволява винаги да имат актуална информацияза уебсайтове, достъпни в интернет и тяхното съдържание.
Основната задача на робота за търсене е да търси нови данни и да ги прехвърля към търсачката за по-нататъшна обработка.

Индексиране
Търсачката е в състояние да намери данни само на сайтове, представени в нейната база данни - с други думи, индексирани. На тази стъпка търсачката трябва да определи дали намерената информация трябва да бъде въведена в базата данни и ако да, в кой раздел. Този процес също се извършва автоматично.
Смята се, че Google индексира почти цялата информация, налична в интернет, докато Yandex подхожда към индексирането на съдържанието по-селективно и не толкова бързо. И двата гиганта за търсене на Runet работят в полза на потребителя, но общите принципи на работа на търсачките Google и Yandex са малко по-различни, тъй като те се основават на уникални софтуерни решения, които съставят всяка система.
Обща точка за търсачките е, че процесът на индексиране на всички нови ресурси отнема повече време от индексирането на ново съдържание на сайтове, известни на системата. Информацията, появяваща се на сайтове, които се ползват с голямо доверие от търсачките, завършва в индекса почти моментално.
Ранжиране
Класирането е оценка от алгоритмите на търсачката за значимостта на индексираните данни и подреждането им в съответствие с фактори, специфични за дадена търсачка. Получената информация се обработва за генериране на резултати от търсенето за целия диапазон от потребителски заявки. Каква информация ще бъде представена горе и долу в резултатите от търсенето зависи изцяло от това как работят избраната търсачка и нейните алгоритми.
Сайтовете в базата данни на търсачката са разделени на теми и групи заявки. За всяка група заявки се генерира предварителен изход, който подлежи на допълнителна корекция. Позициите на повечето сайтове се променят след всяка актуализация на SERP - актуализация на класирането, която се случва ежедневно в Google и на всеки няколко дни в търсенето на Yandex.
Човек като помощник в борбата за качество на доставката
Реалността е, че дори най-напредналите търсачки, като Yandex и Google, в момента все още се нуждаят от човешка помощ, за да генерират резултати, които отговарят на приетите стандарти за качество. Когато алгоритъмът за търсене не работи достатъчно добре, резултатите му се коригират ръчно - чрез оценка на съдържанието на страницата по множество критерии.
Голяма армия от специално обучени хора от различни страни– модератори (оценители) на търсачки – трябва да извършват огромно количество работа всеки ден, за да проверят съответствието на страниците на уебсайта с потребителските заявки, филтриране на резултатите от спам и забранено съдържание (текстове, изображения, видеоклипове). Работата на оценителите позволява по-чисти резултати от търсенето и допринася за по-нататъшното развитие на самообучаващи се алгоритми за търсене.

Заключение
С развитието на интернет и постепенната промяна на стандартите и формите на представяне на съдържанието се променя и подходът към търсенето, усъвършенстват се процесите на индексиране и класиране на информацията, използваните алгоритми и се появяват нови фактори за класиране. Всичко това позволява на търсачките да генерират резултати с най-високо качество, които са адекватни на заявките на потребителите, но в същото време усложнява живота на уеб администраторите и специалистите, участващи в промоцията на уебсайтове.
В коментарите под статията ви каня да говорите коя от основните търсачки на RuNet - Yandex или Google, според вас, работи по-добре, предоставяйки на потребителя по-добро търсене и защо.
Защо маркетологът трябва да знае? основни принципи Оптимизация за търсачки? Просто е: органичен трафике отличен източник на входящ поток целева аудиторияза вашия корпоративен уебсайт и дори целеви страници.
Запознайте се със серия от образователни публикации по темата за SEO.
Какво е търсачка?
Търсачката е голяма база данни от документи (съдържание). Роботите за търсене обхождат ресурси и индексират различни видове съдържание и именно тези запазени документи се класират при търсене.
Всъщност Yandex е „моментна снимка“ на Runet (също Турция и няколко англоезични сайта), а Google е глобалният Интернет.
Индексът за търсене е структура от данни, съдържаща информация за документите и местоположението на ключовите думи в тях.
Според принципа на работа търсачките са подобни една на друга, разликите са във формулите за класиране (подреждане на сайтове в резултатите от търсенето), които се основават на машинно обучение.
Всеки ден милиони потребители изпращат заявки към търсачките.
„Напишете резюме“:

"Купува":

Но най-вече се интересуват...

Как работи търсачката?
За да предостави на потребителите бързи отговори, архитектурата на търсенето беше разделена на 2 части:
- основно търсене,
- метатърсене.
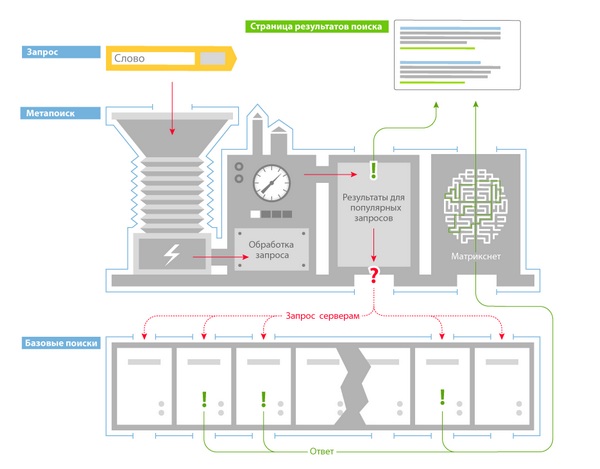
Основно търсене
Базовото търсене е програма, която търси в своята част от индекса и предоставя всички документи, които отговарят на заявката.
Metasearch е програма, която обработва заявка за търсене, определя регионалността на потребителя и ако заявката е популярна, извежда готова опция за търсене, а ако заявката е нова, избира основно търсене и издава команда за избор на документи , след това използва машинно обучение, за да класира намерените документи и да ги предостави на потребителя.

Класификация на заявките за търсене
За да даде подходящ отговор на потребителя, търсачката първо се опитва да разбере от какво конкретно се нуждае. Заявката за търсене се анализира и потребителят се анализира паралелно.
Заявките за търсене се анализират според следните параметри:
- Дължина;
- определение;
- популярност;
- конкурентоспособност;
- синтаксис;
- география.
Тип заявка:
- навигация;
- информационни;
- транзакционен;
- мултимедия;
- общ;
- официален
След анализиране и класифициране на заявката се избира функция за класиране.

Обозначаването на типовете заявки е конфиденциална информацияи предложените опции са догадки на специалисти по оптимизация за търсачки.
Ако потребителят зададе общо запитване, търсачката връща различни видоведокументи. И трябва да разберете, че като популяризирате търговската страница на сайта в ТОП 10 за обща заявка, вие кандидатствате не за попадане в едно от 10-те места, а в броя на местата
за търговски страници, което се подчертава от формулата за класиране. И следователно вероятността за класиране в челните позиции за такива заявки е по-ниска.
Машинно обучение MatrixNet е алгоритъм, въведен през 2009 г. от Yandex, който избира функция за класиране на документи за определени заявки.

MatrixNet се използва не само в търсенето на Yandex, но и за научни цели. Например в Европейския център за ядрени изследвания се използва за редки събития в големи обемиданни (търсене на Хигс бозона).
Първичните данни за оценка на ефективността на формулата за класиране се събират от оценителския отдел. Това са специално обучени хора, които оценяват извадка от сайтове, използвайки експериментална формула според следните критерии.
Оценка на качеството на сайта
Vital - официален уебсайт (Sberbank, LPgenerator). Заявка за търсенесъответства на официалния уебсайт, групи в социалните мрежи, информация за авторитетни ресурси.
Полезен (с оценка 5) - сайт, който предоставя обширна информация при поискване.
Пример - заявка: банер плат.
Сайт, който е оценен като „полезен“, трябва да съдържа следната информация:
- какво е банерна тъкан;
- спецификации;
- снимки;
- видове;
- ценова листа;
- нещо друго.
Примери за заявки в горната част:

Подходящ+ (резултат 4) – Този резултат означава, че страницата е подходяща за заявката за търсене.
Уместно - (резултат 3) - Страницата не отговаря точно на заявката за търсене.
Да приемем, че заявката „Сесии на Пазителите на галактиката“ показва страница за филм без сесии, страница от минала сесия или страница с трейлър в YouTube.
Без значение (оценка 2) - страницата не отговаря на заявката.
Пример: името на хотела показва името на друг хотел.
За да популяризирате ресурс за обща или информационна заявка, трябва да създадете страница, която отговаря на оценката „полезно“.
За ясни заявки е достатъчна оценка „уместно+“.
Уместността се постига чрез текстово и линково съответствие на страницата със заявките за търсене.
заключения
- Не всички заявки могат да бъдат повишени до комерсиална целева страница;
- Не всички искания за информация могат да се използват за популяризиране на търговски уебсайт;
- Когато популяризирате обща заявка, създайте полезна страница.
Често срещана причина, поради която даден сайт не се класира на върха, е, че съдържанието на популяризираната страница не съответства на заявката за търсене.
Ще говорим за това в следващата статия, „Списък за основна оптимизация на уебсайтове“.
Много хора искат да бъдат в ТОП, но не всеки разбира как работят търсачките. И до началото на 2017 г. изискванията за уебсайтове от търсачките станаха още по-строги (повече подробности в статията). Ето защо, за да сте постоянно на върха, първо трябва поне да разберете как работят алгоритмите за търсене.
След като прочетете тази статия до края, ще разберете принципите, на които се основава работата на Yandex и Google, и ще научите малко повече за пощата, rambler и bing. В същото време няма да засягаме факторите за класиране на уебсайтове, защото... Това е много обемен материал, който изисква отделна публикация.
Е, или ако искате целта, целта или дори мисията на търсачката е да даде най-точния отговор на заявката на потребителя под формата на списък с връзки към различни ресурси.
За да генерира висококачествен списък от сайтове, търсачката създава база данни. Тоест, ако вашият сайт или нова страницасайтът не е индексиран от Yandex или Google, което означава, че те няма да бъдат в резултатите от търсенето. База данни от сайтове се формира от търсещи роботи, които предоставят информация за сайтовете на своите "шеф", и той въвежда данните в регистъра. Например, ако сте регистрирали сайта си в или, можете да намерите там информация за това колко страници от вашия сайт са били индексирани от търсачката.
След това целият регистър с данни от страниците на множество сайтове се класира според определени параметри: регион, релевантност на заявката, популярност на ресурса, качество на съдържаниетои така нататък. Както вече казах, ще анализираме целия списък с фактори за класиране в отделна публикация. Основната задача при популяризирането на сайт е да повлияе на тези фактори, за да издигне сайта до ТОП.
Характеристики и характеристики на търсачките през 2018 г
Всички сме виждали Google рекламаза това как търсачка влиза в неравна битка с баба, за да намери най-близката аптека. Какво означава това? Че търсачките се учат и скоро напълно ще спрат да работят с ключови думи и ще работят само със значения. защото това е основната им задача, не да предоставят произволен списък от сайтове, а да помогнат на потребителя да намери място, продукт или услуга.
У нас делът гласово търсеневсе още е много незначителен, но в САЩ заема около 50% мобилен трафик. Това означава, че тази тенденция скоро ще засегне и Русия. Съответно броят на исканията за информация ще се увеличи ( как, къде, къде) и заявки, които не могат да бъдат предвидени, защото те няма да бъдат стереотипни и продиктувани от ситуацията, в която се намира човекът. Например, той стои на кръстовище и ме пита къде да завия, за да намеря кафене, където има възможности за бизнес на стойност до 300 рубли.Това е Google.
Що се отнася до Yandex, който също беше представен в края на 2016 г. Това е алгоритъм, който също ще работи предимно със значения.
Коя търсачка е по-добра или как Yandex се различава от Google?
Сам личен опитМога да кажа, че и двете търсачки са добри по свой начин. Разликата, разбира се, е, че Yandex е руска търсачка, а Google е най-голямата търсачка в света. Разбира се, ние не се интересуваме от външните разлики между сайтовете на тези търсачки и услугите, които предоставят, а как генерират резултати от търсенето, тъй като те се различават много.
Yandex обръща повече внимание на регионалното търсене. Тоест, ако сте във Владивосток и въведете заявка, без да посочвате град или регион, например „прозорци“, първо Yandex ще покаже уебсайтовете на онези компании, които се намират във Владивосток и по някакъв начин са свързани с прозорци.
За Google популярността и цитирането на даден ресурс (а не само връзките към вашия сайт) са по-важни; въз основа на това той прави заключение дали вашият сайт е полезен.
Що се отнася до другите търсачки, тогава mail.ruе обвивка на резултатите от търсенето с Google, т.е. Самият mail.ru не анализира нищо, а просто показва това, което Google би показал. Rambler.ruПо същия принцип това е черупка на Yandex.