Борба с дублирани страници. Правилни методи за премахване на дублиращи се страници Правилна работа с дублирани страници
Доста често има копия на страници на един и същи сайт, а собственикът му може дори да не знае за това. Когато ги отворите, всичко се показва правилно, но ако погледнете адреса на сайта, ще забележите, че различни адреси могат да съответстват на едно и също съдържание.
Какво означава това? За обикновени потребителив Москва нищо, защото са дошли на вашия сайт не за да гледат заглавията на страниците, а защото са се интересували от съдържанието. Но около търсачкитова не може да се каже, тъй като те възприемат това състояние на нещата в съвсем различна светлина - виждат страници, които са различни една от друга с еднакво съдържание.
Ако редовни потребителиТе може да не забележат дублиращи се страници в сайта, но това определено няма да убегне от вниманието на търсачките. До какво може да доведе това? Роботите за търсене ще идентифицират копията като различни страници и в резултат на това вече няма да възприемат тяхното съдържание като уникално. Ако се интересувате от промоция на уебсайтове, тогава знайте, че това със сигурност ще повлияе на класирането. В допълнение, наличието на дубликати ще намали сока на връзката, който се появи в резултат на значителни усилия от страна на оптимизатора, който се опита да подчертае целевата страница. Дублиращите се страници могат да доведат до осветяване на напълно различна част от сайта. И това може значително да намали ефективността външни връзкии вътрешно свързване.
Могат ли дублиращите се страници да навредят?
Често виновник за появата на дубликати е CMS, чиито неправилни настройки или липсата на внимание на оптимизатора може да доведе до генериране на ясни копия. Системите за управление на уебсайтове като Joomla често страдат от това. Нека веднага да отбележим, че универсален лекПросто няма начин да се борите с това явление, но можете да инсталирате някой от плъгините, предназначени за търсене и изтриване на копия. Възможно е обаче да се появят неясни дубликати, чието съдържание не съвпада напълно. Това най-често се случва поради недостатъци на уеб администратора. Често такива страници могат да бъдат намерени в онлайн магазини, в които продуктовите карти се различават само в няколко изречения от описанието, докато останалото съдържание, което се състои от различни елементи и блокове от край до край, е същото. Експертите често са съгласни, че определен брой дубликати няма да пречат на сайта, но ако има около половината или повече от тях, тогава популяризирането на ресурса ще създаде много проблеми. Но дори и в случаите, когато има няколко копия на сайта, по-добре е да ги намерите и премахнете - по този начин със сигурност ще се отървете от дубликати на вашия ресурс.
Намиране на дублирани страници
Има няколко начина за намиране на дублирани страници. Но преди самото търсене би било добре да погледнете вашия сайт през очите на търсачките: как те си го представят. За да направите това, просто сравнете броя на вашите страници с тези, които са в техния индекс. За да видите това, просто влезте в търсачката Google низили фразата Yandex host:yoursite.ru, след което оценете резултатите.
Ако такава проста проверка предоставя различни данни, които могат да се различават 10 или повече пъти, тогава има причина да се смята, че вашият електронен ресурс съдържа дубликати. Въпреки че това не винаги може да се дължи на дублиращи се страници, тази проверка ще предостави добра основа за намирането им. Ако вашият сайт е малък, тогава можете самостоятелно да преброите броя на реалните страници и след това да сравните резултата с индикаторите на търсачката. Можете също да търсите дубликати, като използвате URL адреси, които се предлагат в резултатите от търсенето. Ако използвате CNC, тогава страници със странни знаци в URL адреса, като например “index.php?с=0f6b3953d”, веднага ще привлекат вниманието ви.
Друг метод за определяне на наличието на дубликати е търсенето на текстови фрагменти. За да извършите такава проверка, трябва да въведете няколко думи текст от всяка страница в лентата за търсене, след което просто да анализирате резултата. В случаите, когато две или повече страници се появяват в резултатите от търсенето, става очевидно, че има копия. Ако има само една страница в резултатите от търсенето, тогава тя няма дубликати. Разбира се, тази техника за проверка е подходяща само за малък сайт, състоящ се от няколко страници. Когато един сайт съдържа стотици от тях, неговият оптимизатор може да използва специални програми, например Xenu`s Link Sleuth.
За да проверите сайта, отворете нов проекти отидете в менюто „Файл“, намерете „Проверете URL“, въведете адреса на сайта, който ви интересува, и щракнете върху „OK“. Сега програмата ще започне да обработва всички URL адреси на посочения ресурс. Когато работата приключи, получената информация ще трябва да се отвори във всеки удобен редактор и да се търси дубликати. Методите за намиране на дублирани страници не свършват дотук: в лентата с инструменти на Google Webmaster и Yandex.Webmaster можете да видите инструменти, които ви позволяват да проверявате индексирането на страници. С тяхна помощ можете да намерите и дубликати.
По пътя към решаването на проблема
Когато намерите всички дубликати, ще бъдете натоварени със задачата да ги елиминирате. Има няколко възможности за решаване на този проблем и различни начини за премахване на дублиращи се страници.
Обединяването на копирани страници може да се извърши с помощта на пренасочване 301. Това е ефективно в случаите, когато URL адресите се отличават с липсата или присъствието на www. Можете също да изтриете дублиращи се страници ръчно, но този метод е успешен само за тези дубликати, които са създадени ръчно.
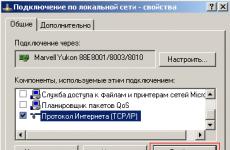
Можете да решите проблема с дубликатите, като използвате каноничния етикет, който се използва за неясни копия. Така може да се използва в онлайн магазин за продуктови категории, за които има дубликати и които се различават само чрез сортиране по различни параметри. Освен това каноничният етикет е подходящ за използване на страници за печат и подобни ситуации. Използването му не е никак трудно - за всяко копие се задава атрибут във формата rel=”canonical”; за популяризираната страница с най-подходящи характеристики този атрибут не е посочен. Приблизителен изглед на кода: връзка rel="canonical" href="http://site.ru/stranica-kopiya"/. Той трябва да се намира в областта на етикета на главата.
Правилно конфигуриран файл robots.txt също ще ви позволи да постигнете успех в борбата с дубликатите. С помощта на директивата Disallow можете да блокирате достъпа на роботите за търсене до всички дублирани страници.
Дори професионалното разработване на уебсайтове няма да помогне да го доведете до ТОП, ако ресурсът съдържа дублирани страници. Днес страниците за копиране са един от най-честите капани, от които страдат начинаещите. Голям брой от тях на вашия сайт ще създадат значителни трудности при извеждането му в ТОП или дори ще го направят невъзможно.
Здравейте всички! В последната статия засегнахме важна тема - търсене на дублирани страници на уебсайтове. Както показаха коментарите и няколко писма, които дойдоха при мен, тази тема е актуална. Дублираното съдържание в нашите блогове, техническите недостатъци в CMS и различните проблеми с шаблоните не дават на нашите ресурси пълна свобода в търсачкио Затова трябва да се борим сериозно с тях. В тази статия ще научим как да премахваме дублиращи се страници от всеки уебсайт; примерите в това ръководство ще покажат как да се отървете от тях по прост начин. От нас се изисква просто да използваме придобитите знания и да наблюдаваме последващите промени в индексите на търсачките.
Моята история за борба с дубликати
Преди да разгледаме начините за премахване на дубликати, ще ви разкажа моята история за справяне с дубликати.
Преди две години (25 май 2012 г.) получих обучителен блог за специализираните курсове SE0. Дадена ми е, за да упражнявам придобитите знания по време на обучението. В резултат на това за два месеца практика успях да създам няколко страници, дузина публикации, куп тагове и цяла кола дубликати. През следващите шест месеца, когато образователният блог стана мой личен уебсайт, други дубликати бяха добавени към тази композиция в индекса на Google. Това се случи по вина на replytocom поради нарастващия брой коментари. Но в базата данни на Yandex броят на индексираните страници нараства постепенно.
В началото на 2013 г. забелязах специфичен спад в позициите на моя блог в Google. Тогава започнах да се чудя защо се случва това. В крайна сметка стигнах дотам, че открих голям брой дубликати в тази търсачка. Разбира се, започнах да търся варианти за премахването им. Но моите търсения на информация не доведоха до нищо - не намерих никакви разумни ръководства в интернет за премахване на дублиращи се страници. Но успях да видя една бележка в един блог за това как можете да премахнете дубликати от индекса с помощта на файла robots.txt.
Първо, написах куп забраняващи директиви за Yandex и Google, за да забранят сканирането на определени дублирани страници. След това, в средата на лятото на 2013 г., използвах един метод за премахване на дубликати от индекса на Google (ще научите за него в тази статия). По това време индексът на тази търсачка е натрупал повече от 6000 дубликата! И това е само с пет страници и повече от 120 публикации в блога ви...
След като внедрих моя метод за премахване на дубликати, броят им започна бързо да намалява. По-рано тази година използвах друга опция за премахване на дубликати, за да ускоря процеса (ще научите и за нея). И сега в моя блог броят на страниците в индекса на Google се доближава до идеалния - днес в базата данни има около 600 страници. Това е 10 пъти по-малко от преди!
Как да премахнете дублиращи се страници - основни методи
Има няколко по различни начиниборба с дубликати. Някои опции ви позволяват да предотвратите появата на нови дубликати, докато други могат да се отърват от старите. Разбира се, най-добрият вариант е ръчно. Но за да го приложите, трябва да имате добро разбиране на CMS на вашия уебсайт и да знаете как работят алгоритмите на търсачката. Но други методи също са добри и не изискват специални познания. Сега ще говорим за тях.
Този метод се счита за най-ефективният, но и най-взискателният от гледна точка на познания по програмиране. Въпросът е, че тук е написано необходими правилавъв файла .htaccess (намиращ се в корена на директорията на сайта). И ако те са написани с грешка, тогава може не само да не успеете да решите задачата за премахване на дубликати, но и да премахнете целия сайт от интернет.
Как се решава проблемът с премахването на дубликати чрез пренасочване 301? Базира се на концепцията за пренасочване на роботи за търсене от една страница (от дубликат) към друга (оригинал). Тоест, роботът стига до дубликат на някаква страница и с помощта на пренасочване се появява на оригиналния документ на сайта, от който се нуждаем. След това започва да го изучава, като пропуска кадър извън полезрението си.

С течение на времето, след регистриране на всички варианти на това пренасочване, еднакви страници се залепват и дублиращите се изпадат от индекса. Следователно тази опция почиства идеално вече индексираните дублирани страници. Ако решите да използвате този метод, не забравяйте да проучите синтаксиса за създаване на пренасочвания, преди да добавите правила към файла .htaccess. Например, препоръчвам да изучавате ръководство за 301-во пренасочване от Саша Алаев.
Създаване на канонична страница
Този метод се използва, за да посочи на търсачката документа от целия набор от негови дубликати, които трябва да бъдат в главния индекс. Тоест такава страница се счита за оригинална и участва в резултатите от търсенето.
За да го създадете, трябва да напишете код с URL адреса на оригиналния документ на всички дублирани страници:
Разбира се, тромаво е да пишете всичко това ръчно. Има различни добавки за това. Например, за моя блог, който работи на WordPress двигателя, посочих този код с помощта на плъгина „Всичко в един SEO пакет“. Това се прави много просто - поставете отметка в съответното квадратче в настройките на приставката:

За съжаление опцията за канонична страница не премахва дублиращите се страници, а само предотвратява по-нататъшното им появяване. За да се отървете от вече индексирани дубликати, можете да използвате следния метод.
Директива Disallow в robots.txt
Файлът robots.txt е инструкция за търсачките, която им казва как да индексират нашия сайт. Без този файл робот за търсене може да достигне до почти всички документи на нашия ресурс. Но нямаме нужда от такава свобода от паяка за търсене - не искаме да виждаме всички страници в индекса. Това важи особено за дубликати, които се появяват поради неадекватност на шаблона на сайта или наши грешки.
Ето защо е създаден такъв файл, в който са разписани различни директиви за забрана и разрешаване на индексиране от търсачките. Можете да предотвратите сканирането на дублиращи се страници с помощта на директивата Disallow:

Когато създавате директива, трябва също така да съставите правилно забраната. В крайна сметка, ако направите грешка при попълване на правилата, тогава резултатът може да бъде напълно различно блокиране на страница. Така можем да ограничим достъпа до необходимите страници и да позволим на други дубликати да изтекат. Но все пак грешките тук не са толкова лоши, колкото при създаването на правила за пренасочване в .htaccess.
Забраната за индексиране чрез Disallow важи за всички роботи. Но не за всички, тези забрани позволяват на търсачката да премахва забранените страници от индекса. Например Yandex в крайна сметка премахва дублиращите се страници, блокирани в robots.txt.
Но Google няма да изчисти своя индекс от ненужни боклуци, посочени от уеб администратора. Освен това директивата Disallow не гарантира това блокиране. Ако има външни връзки към страници, забранени в инструкциите, те в крайна сметка ще се появят в базата данни на Google .
Отървете се от дубликати, индексирани в Yandex и Google
И така, разбрахме различните методи, време е да разберем план стъпка по стъпкапремахване на дубликати в Yandex и Google. Преди почистване трябва да намерите всички дублирани страници - писах за това в предишна статия. Трябва да видите пред очите си кои елементи от адресите на страниците се отразяват в дубликати. Например, ако това са страници с дървовидни коментари или пагинация, тогава записваме думите „replytocom“ и „страница“ в техните адреси:

Отбелязвам, че в случай на replytocom можете да използвате не тази фраза, а просто въпросителен знак. В края на краищата той винаги присъства в адреса на страниците с коментари в дърво. Но тогава трябва да запомните, че URL адресите на оригиналните нови страници не трябва да съдържат символа „?“, в противен случай тези страници също ще бъдат забранени.
Почистване на Yandex
За да премахнем дубликати в Yandex, ние създаваме правила за блокиране на дубликати с помощта на директивата Disallow. За да направим това, извършваме следните действия:
- Отворете специалния инструмент „Анализ на Robot.txt“ в Yandex Webmaster.
- Добавяме нови правила за блокиране на дублирани страници към полето за директиви.
- В полето “URL list” въвеждаме примери за дублиращи се адреси за новите директиви.
- Кликнете върху бутона „Проверка“ и анализирайте резултатите.

Ако сме направили всичко правилно, тогава този инструмент ще покаже, че има блокиране според новите правила. В специалното поле „Резултати от проверка на URL“ трябва да видим червен надпис за забраната:

След проверка трябва да изпратим създадените дублирани директиви към истинския файл robots.txt и да го пренапишем в директорията на нашия сайт. И тогава просто трябва да изчакаме, докато Yandex автоматично изтрие нашите дубликати от своя индекс.
Почистване на Google
 Не е толкова просто с Google. Забранените директиви в robots.txt не премахват дубликати в индекса на тази търсачка. Следователно ще трябва да направим всичко сами. За щастие има отлична услуга за уеб администратори на Google за това. По-конкретно, ние се интересуваме от неговия инструмент „URL параметри“.
Не е толкова просто с Google. Забранените директиви в robots.txt не премахват дубликати в индекса на тази търсачка. Следователно ще трябва да направим всичко сами. За щастие има отлична услуга за уеб администратори на Google за това. По-конкретно, ние се интересуваме от неговия инструмент „URL параметри“.
Именно благодарение на този инструмент Google позволява на собственика на сайта да предостави на търсачката информация за това как трябва да обработва определени параметри в URL адреса. Интересуваме се от възможността да покажем на Google онези параметри на адреси, чиито страници са дублирани. И това са тези, които искаме да премахнем от индекса. Ето какво трябва да направим за това (например, нека добавим параметър за премахване на дубликати от replytocom):
- Отворете инструмента „URL Options“ в услугата на Google от раздела на менюто „Crawling“.
- Щракнете върху бутона „Добавяне на параметър“, попълнете формата и запазете новия параметър:

В резултат на това получаваме писмено правило за Google да преглежда своя индекс за наличие на дублирани страници. По този начин допълнително определяме следните параметри за други дубликати, от които искаме да се отървем. Например, ето как изглежда част от моя списък с написани правила за Google, така че да коригира своя индекс:

Това приключва нашата работа по почистването на Google и моята публикация приключи. Надявам се, че тази статия ще ви донесе практическа полза и ще ви позволи да се отървете от дублиращи се страници от вашите ресурси.
С уважение, Вашият Максим Довженко
P.S. Приятели, ако трябва да направите видео по тази тема, пишете ми в коментарите към тази статия.
Дублирани страници в уебсайтове или блогове, откъде идват и какви проблеми могат да създадат.
Точно за това ще говорим в тази публикация, ще се опитаме да разберем този феномен и да намерим начини да минимизираме потенциалните проблеми, които могат да ни донесат дублиращите се страници в сайта.
Така че нека продължим.
Какво представляват дублиращите се страници?
Дублиране на страници на всеки уеб ресурсозначава достъп до една и съща информация на различни адреси. Такива страници се наричат още вътрешни дубликати на сайта.
Ако текстовете на страницата са напълно идентични, тогава такива дубликати се наричат пълни или ясни. Ако има частично съвпадение снимките се наричат непълни или неясни.
Непълни вземания– това са страници с категории, страници със списъци с продукти и подобни страници, съдържащи съобщения за материали на сайта.
Пълни дублирани страници– това са версии за печат, версии на страници с различни разширения, архивни страници, търсения в уебсайтове, страници с коментари и др.
Източници на дублирани страници.
 В момента повечето дубликати на страници се генерират от използване на съвременна CMS– системи за управление на съдържанието, наричани още машини за уебсайтове.
В момента повечето дубликати на страници се генерират от използване на съвременна CMS– системи за управление на съдържанието, наричани още машини за уебсайтове.
Това и WordPress и Joomla и DLEи други популярни CMS. Това явление сериозно натоварва оптимизаторите на уебсайтове и уеб администраторите и им създава допълнителни проблеми.
В онлайн магазинидубликати могат да се появят при показване на продукти, сортирани по различни данни (производител на продукта, предназначение на продукта, дата на производство, цена и др.).
Трябва да помним и прословутите WWW префикси да решите дали да го използвате в името на домейна, когато създавате, развивате, популяризирате и популяризирате сайта.
Както можете да видите, източниците на дубликати могат да бъдат различни, изброих само основните, но всички те са добре известни на специалистите.
Дублиращите се страници са отрицателни.
Въпреки факта, че много хора не обръщат особено внимание на появата на дубликати, това явление може да създаде сериозни проблеми с промоцията на уебсайта.
Търсачката може да вземе предвид дубликатите са като спами в резултат на това сериозно намаляват позициите както на тези страници, така и на сайта като цяло.
При популяризиране на сайт с връзки може да възникне следната ситуация. В един момент търсачката ще вземе предвид най-много съответна дублирана страница, а не този, който рекламирате с връзки и всичките ви усилия и разходи ще бъдат напразни.
Но има хора, които опитват използвайте дубликати, за да наддадете на теглодо необходимите страници, например главната страница или всяка друга.
Методи за справяне с дублиращи се страници
Как да избегнем дубликати или как да елиминираме негативните аспекти, когато се появят?
И като цяло, струва ли си да се борим с това по някакъв начин или да оставим всичко на милостта на търсачките. Нека се разберат сами, щом са толкова умни.
Използване на robots.txt
Robots.txt– това е файл, който се намира в главната директория на нашия сайт и съдържа директиви за роботи за търсене.
В тези директиви ние определяме кои страници от нашия сайт да индексираме и кои не. Можем също така да посочим името на основния домейн на сайта и файла, съдържащ картата на сайта.
За да предотвратите индексиране на страници използва се директивата Disallow. Това е, което уеб администраторите използват, за да блокират дублиращите се страници от индексиране, и не само дубликатите, но и всяка друга информация, която не е пряко свързана със съдържанието на страниците. Например:
Disallow: /search/ - затваряне на страниците за търсене в сайта
Забрана: /*? — затваряне на страници, съдържащи въпросителен знак „?“
Disallow: /20* — затваряне на архивните страници
Използване на файла .htaccess
Файл.htaccess(без разширение) също се намира в основната директория на сайта. За борба с дубликатите този файл е конфигуриран да използва 301 пренасочвания.
Този метод помага добре за поддържане на ефективността на сайта, когато промяна на CMS на сайта или промяна на неговата структура.Резултатът е правилно пренасочване без загуба на маса на връзката. В този случай теглото на страницата на стария адрес ще бъде прехвърлено към страницата на новия адрес.
301 редиректи се използват и при определяне на основния домейн на даден сайт – с WWW или без WWW.
Използване на етикета REL = „CANNONICAL“
Използвайки този таг, уеб администраторът посочва на търсачката оригиналния източник, т.е. страницата, която трябва да бъде индексирана и да участва в класирането на търсачките. Страницата обикновено се нарича канонична. Записът в HTML кода ще изглежда така:
Когато използвате CMS WordPress, това може да стане в настройките на такъв полезен плъгин като All in One Seo Pack.
Допълнителни мерки срещу дублиране за CMS WordPress
След като приложих всички горепосочени методи за справяне с дублиращи се страници в моя блог, винаги имах чувството, че не съм направил всичко възможно. Затова, след като се порових в интернет и се консултирах с професионалисти, реших да направя нещо друго. Сега ще го опиша.
Реших да премахна дубликатите, които се създават в блога, когато с помощта на котвиГоворих за тях в статията „HTML Anchors“. В блогове, работещи с CMS WordPress, котвите се формират, когато се приложи етикетът "#more" и при използване на коментари. Целесъобразността от използването им е доста спорна, но те очевидно произвеждат дубликати.
Сега как поправих този проблем.
Нека първо се заемем с етикета #more.
Намерих файла, където се генерира. Или по-скоро ми казаха.
Това е../wp-includes/post-template.php
След това намерих фрагмент от програмата:
ID)\» class= \»more-link\»>$more_link_text", $more_link_text);
Маркираният в червено фрагмент беше отстранен
#more-($post->ID)\» class=
И завърших с ред като този.
$output .= apply_filters('the_content_more_link', ' $more_link_text", $more_link_text);
Премахване на котви за коментари #comment
Сега да преминем към коментарите. Вече се сетих за това.
Реших и файла ../wp-includes/comment-template.php
Намиране на необходимата част от програмния код
връщане apply_filters('get_comment_link', $link . „#коментирай-“. $comment->comment_ID, $comment, $args);)
По същия начин фрагментът, маркиран в червено, беше премахнат. Много спретнат, внимателен, точно до всяка точка.
. „#коментирай-“. $comment->comment_ID
Завършваме със следния ред програмен код.
връщане apply_filters('get_comment_link', $link, $comment, $args);
}
Естествено, направих всичко това, след като копирах указаното програмните файловена вашия компютър, така че в случай на повреда можете лесно да възстановите състоянието на промените.
В резултат на тези промени, когато щракна върху текста „Прочетете останалата част от записа...“, получавам страница с каноничния адрес и без добавяне на опашка към адреса под формата на „#more-. ..”. Освен това, когато щракна върху коментар, получавам нормален каноничен адрес без префикс във формата „#comment-...“.
По този начин броят на дублиращите се страници в сайта леко е намалял. Но сега не мога да кажа какво друго ще формира нашият WordPress. Ще следим проблема допълнително.
И в заключение предлагам на вашето внимание едно много добро и образователно видео по тази тема. Силно препоръчвам да го гледате.
Здраве и успех на всички. До следващия път.
Полезни материали:

Какво представляват дублиращи се страници- това са страници с абсолютно еднакво съдържание и различни URL адреси.
Може да има няколко причини за дублиране на страници в уебсайт, но почти всички от тях са по един или друг начин свързани със системата за управление на съдържанието на сайта. Най-добре е да вземете мерки за предотвратяване на появата на дублиращи се страници на етапа на създаване на сайта. Ако вашият сайт вече функционира, не забравяйте да проверите за дублиращи се страници, в противен случай сериозни проблеми с индексирането и SEO не могат да бъдат избегнати.
Има няколко начина да се отървете от дублирани страници на уебсайтове. Някои могат да помогнат в борбата със съществуващите копия на страници, докато други могат да помогнат за предотвратяването им да се появяват в бъдеще.
Как да намерите дублиращи се страници на уебсайт?
Но първо трябва да проверите дали има дублирани страници във вашия ресурс и ако има, какъв тип страници са те. Как да го направим?
- Метод 1. Заявка за търсене „site:“
Можете да използвате командата "site:". Тази команда връща резултати от търсенето за конкретен сайт. Като въведете site:www.yoursite.com/page1, ще видите дали има дубликати на тази страница в търсенето.
- Метод 2. Търсене по откъс от статия
Избираме малко парче текст от страницата, за която търсим дубликати, и го поставяме в търсенето. Резултатите от търсенето веднага ще покажат всички индексирани дубликати на желаната страница.
Как да се справим с дублиращи се страници?
301 пренасочване
Един от най-ефективните, но в същото време и най-трудните методи за справяне с дубликати е пренасочването 301; то слепва посочените страници и дубликатите изчезват от индекса на търсачката с течение на времето.
Когато робот за търсене попадне на дублирана страница с пренасочване 301, уеб сървърът автоматично ще го пренасочи към оригиналната страница. Всички пренасочвания се записват във файла .htaccess, който се намира в основната директория на сайта. Не трябва да използвате пренасочване 301 (постоянно пренасочване), ако планирате да използвате страницата за копиране по някакъв начин в бъдеще. Можете да използвате пренасочване 302 (временно) за това. Тогава страниците няма да се слепват.
Когато използвате 301 пренасочване за изтриване дублирани странициОт индекса, на първо място, трябва да вземете решение за основното огледало на сайта. Например като основно огледало посочваме http://site.ruВсичко, което трябва да направите, е да го промените на адреса на вашия уебсайт
- 301 Пренасочване от www.site.ru към site.ru
За да направите това, трябва да добавите следните редове във файла .htaccess (файлът се намира в корена на сайта) веднага след RewriteEngine On :
RewriteCond %(HTTP_HOST) ^www.site.ru$ RewriteRule ^(.*)$ http://site.ru/$1
- 301 пренасочване от site.ru/index.php към site.ru
RewriteRule ^index\.php$ http://site.ru/
По подобен начин можете да се отървете от дубликати като:
http://site.ru/index
http://site.ru/index.html
http://site.ru/index.htm
Ако например искате да обедините страниците http://site.ru и http://site.ru /page123, тогава във файла .htaccess трябва да запишете следното:
Пренасочване 301 /страница 123 http://site.ru
Сега, когато се опитате да получите достъп до страницата http://site.ru/page123, ще бъдете пренасочени към главната страница.
Друг начин за обозначаване на оригинала е да се напише т.нар. канонични връзки. Това са връзки с атрибута rel=каноничен, с други думи, в главния блок на такава страница е написано:
Ако търсачките срещнат такава връзка, те разбират кое от многобройните копия на страниците е оригиналът и го индексират.
Например в горния пример сайтът имаше 2 дублирани страници:
http://site.ru/load
http://site.ru/load/
Като посочим атрибута rel=canonical на страницата http://site.ru/load, ще покажем на търсачките, че тази страница е основната и тя трябва да бъде индексирана.
Някои CMS (например Joomla!) могат автоматично да създават такива връзки, докато при други тази операция се извършва от различни добавки. Въпреки това, дори ако всички новосъздадени дублирани страници на вашия сайт имат канонични връзки, това няма да помогне за решаването на проблема със съществуващите дубликати.
robots.txt
Частично проблемът с дублиращите се страници се решава от файла robots.txt, който съдържа препоръки към търсачките със списък от файлове и папки, които не трябва да се индексират. Защо частично? Тъй като този файл съдържа препоръки, а не правила, и някои търсачки пренебрегват тези препоръки.
Например, за да може Yandex да премахне старите дублирани страници от индекса, достатъчно е да напишете съответните правила, забраняващи тяхното индексиране в robots.txt. С Google ситуацията е малко по-сложна. Същите правила ще трябва да бъдат включени в специален инструментариум от Google, предназначен специално за уеб администратори. В Google уеб администраторът ще трябва да зададе необходимите параметри на връзката в секцията „Обхождане“.
Когато създаваме robots.txt, ще трябва да използваме директивата Disallow.
- Коригирайте robots.txt за Joomla
Потребителски агент: *
Забрани: /администратор/
Disallow: /кеш/
Disallow: /включва/
Disallow: /език/
Disallow: /библиотеки/
Disallow: /медия/
Disallow: /модули/
Disallow: /плъгини/
Disallow: /шаблони/
Забрана: /tmp/
Карта на сайта: http://site.ru /sitemap.xml Потребителски агент: Yandex
Забрани: /администратор/
Disallow: /кеш/
Disallow: /включва/
Disallow: /език/
Disallow: /библиотеки/
Disallow: /медия/
Disallow: /модули/
Disallow: /плъгини/
Disallow: /шаблони/
Забрана: /tmp/
Забрана: /xmlrpc/
Домакин: site.ru
Карта на сайта: http:// site.ru /sitemap.xml
- Коригирайте robots.txt за Wordpress
Потребителски агент: *
Забрана: /wp-admin
Забрана: /wp-includes
Забрана: /wp-content/cache
Забрана: /wp-content/themes
Забрана: /trackback
Забрана: */trackback
Забрана: */*/trackback
Забрана: */*/feed/*/
Забрана: */feed
Забрана: /*?*
Забрана: /tag
Карта на сайта: http://site.ru/sitemap.xml Потребителски агент: Yandex
Забрана: /wp-admin
Забрана: /wp-includes
Забрана: /wp-content/plugins
Забрана: /wp-content/cache
Забрана: /wp-content/themes
Забрана: /trackback
Забрана: */trackback
Забрана: */*/trackback
Забрана: */*/feed/*/
Забрана: */feed
Забрана: /*?*
Забрана: /tag
Домакин: site.ru
Карта на сайта: http://site.ru/sitemap.xml
Какво означават тези редове:
- Потребителски агент: *- правилата, описани под този ред, ще се прилагат за всички роботи за търсене
- Потребителски агент: Yandex- правилата важат само за робота Yandex
- Позволява:- позволяват индексиране (обикновено не е написано)
- Забрана:Забранено е индексирането на страници, чиито адреси съдържат описаното в реда.
- Домакин: site.ru- Основно огледало на сайта
- Карта на сайта:- връзка към XML карта на сайта
- "*" - произволна последователност от знаци в адреса на страницата
Борба с дублирани страници в Wordpress
Вече обсъдихме по-горе какъв трябва да бъде файлът robots.txt за Wordpress. Сега нека поговорим за плъгини, които ви позволяват да се справяте с дубликати и като цяло са незаменими за оптимизатор на уебсайтове на този двигател.
Yoast SEO- Един от най-популярните плъгини за Wordpress, който ви позволява да се справите с проблема с дубликатите. С негова помощ можете да принудите Wordpress да регистрира канонични връзки, да забраните индексирането на пагинирани страници (категории), да скриете авторските архиви, да премахнете /category/ от URL адреса и много други.
Всичко в един Seo пакет- Подобен плъгин, не по-малко популярен и изпълняващ подобни функции. Кое да използвате зависи от вас.
Как да премахнете дублиращи се страници в Joomla
Въпреки че Joomla! поддържа автоматично създаванеканонични връзки, някои дубликати все пак може да попаднат в индекса на търсачката. За борба с дубликатите в Joomla! можете да използвате robots.txt и 301 redirect. Правилен файл rorbots.txt е описан по-горе.
Е, за да активирате CNC (четими от човека URL адреси) в Joomla, просто преименувайте htaccess.txt на .htaccess и го добавете там веднага след RewriteEngine On:
RewriteCond %(HTTP_HOST) ^www.site.ru$
RewriteRule ^(.*)$ http://site.ru/$1 RewriteCond %(THE_REQUEST) ^(3,9)\ /index\.php\ HTTP/
RewriteRule ^index\.php$ http://site.ru/
И също така в настройките на сайта поставете отметки в следните квадратчета:

По този начин ще се отървем от дубликати като www.site.ru и site.ru /index.php, защото тази CMS има този проблем с дубликати. И търсачките често индексират страници като site.ru/index.php. Сега, след всички манипулации, при опит за достъп до страница, например www.site.ru, посетителят ще бъде пренасочен към главната страница, т.е. site.ru.
Сред плъгините за Joomla мога да препоръчам JL Без двойки- плъгин премахва дублиращи се страници в компонента com_content. Възможно пренасочване 301 към правилна страница, или изход за грешка 404.
Специални услуги за създаване на robots.txt и .htaccess
Ако тепърва започвате да овладявате изграждането на уебсайтове, опитайте да използвате услугите на специализирани услуги, които ще ви помогнат да генерирате валидни файлове robots.txt и .htaccess:
seolib.ru- На него можете не само да създавате, но и да тествате вашия robots.txt
htaccess.ru -една от най-популярните услуги, където можете да създавате и избирате различни параметри за генерирания .htaccess файл
Собственикът може дори да не подозира, че някои страници на сайта му имат копия - най-често това е така. Страниците се отварят, всичко е наред със съдържанието им, но ако просто обърнете внимание на URL адреса, ще забележите, че адресите са различни за едно и също съдържание. Какво означава? За потребителите на живо, абсолютно нищо, тъй като те се интересуват от информацията на страниците, но бездушните търсачки възприемат това явление съвсем различно - за тях това са напълно различни страници с едно и също съдържание.
Вредни ли са дублиращите се страници?
Така че, ако обикновен потребител дори не може да забележи наличието на дубликати на вашия сайт, тогава търсачките веднага ще определят това. Каква реакция да очаквате от тях? Тъй като роботите за търсене по същество виждат копията като различни страници, съдържанието на тях престава да бъде уникално. А това вече се отразява негативно на класирането.
Освен това наличието на дубликати замъглява сока от връзки, който оптимизаторът се е опитал да концентрира върху целевата страница. Поради дубликати може да се окаже на съвсем различна страница от тази, на която са искали да го преместят. Това означава, че ефектът от вътрешните връзки и външните връзки може да бъде значително намален.
В по-голямата част от случаите CMS е виновен за появата на дубликати - поради неправилни настройки и липса на необходимото внимание от страна на оптимизатора се генерират ясни копия. Това е проблемът с много CMS, например Joomla. Трудно е да се намери универсална рецепта за решаване на проблема, но можете да опитате да използвате някой от плъгините за изтриване на копия.
Появата на неясни дубликати, в които съдържанието не е напълно идентично, обикновено се дължи на грешка на уеб администратора. Такива страници често се срещат в сайтове на онлайн магазини, където страниците с продуктови карти се различават само в няколко изречения с описание, а цялото останало съдържание, състоящо се от блокове от край до край и други елементи, е същото.
Много експерти твърдят, че малък брой дубликати няма да навредят на сайта, но ако има повече от 40-50%, тогава ресурсът може да срещне сериозни трудности по време на промоцията. Във всеки случай, дори и да няма много копия, струва си да се погрижите за тях, така че гарантирано ще се отървете от проблеми с дубликати.
Намиране на копирани страници
Има няколко начина за намиране на дублирани страници, но първо трябва да се свържете с няколко търсачки и да видите как виждат вашия сайт - просто трябва да сравните броя на страниците в индекса на всяка. Това е доста лесно да се направи, без да се прибягва до допълнителни средства: в Yandex или Google просто въведете host:yoursite.ru в лентата за търсене и погледнете броя на резултатите.
Ако след такава проста проверка количеството се различава значително, с 10-20 пъти, тогава това с известна степен на вероятност може да показва съдържанието на дубликати в един от тях. Копирането на страници може да не е виновно за тази разлика, но въпреки това води до допълнително, по-задълбочено търсене. Ако сайтът е малък, тогава можете ръчно да преброите броя на реалните страници и след това да ги сравните с индикатори от търсачките.
Можете да търсите дублирани страници по URL адрес в резултатите на търсачката. Ако трябва да имат CNC, тогава страници с URL адреси, съдържащи неразбираеми знаци, като „index.php?s=0f6b2903d“, веднага ще се откроят от общия списък.
Друг начин за определяне на наличието на дубликати с помощта на търсачки е търсенето в текстови фрагменти. Процедурата за такава проверка е проста: трябва да въведете текстов фрагмент от 10-15 думи от всяка страница в лентата за търсене и след това да анализирате резултата. Ако има две или повече страници в резултатите от търсенето, тогава има копия, но ако има само един резултат, тогава тази страница няма дубликати и не е нужно да се притеснявате.
Логично е, че ако сайтът се състои от голям брой страници, тогава такава проверка може да се превърне в непосилна задача за оптимизатора. За да минимизирате разходите за време, можете да използвате специални програми. Един от тези инструменти, който вероятно е познат на опитни професионалисти, е програмата Link Sleuth на Xenu.
За да проверите сайта, трябва да отворите нов проект, като изберете „Проверка на URL“ от меню „Файл“, въведете адреса и щракнете върху „ОК“. След това програмата ще започне да обработва всички URL адреси на сайтове. В края на проверката трябва да експортирате получените данни във всеки удобен редактор и да започнете да търсите дубликати.
В допълнение към горните методи, панелите Yandex.Webmaster и Google Webmaster Tools имат инструменти за проверка на индексирането на страници, които могат да се използват за търсене на дубликати.
Методи за решаване на проблема
След като бъдат открити всички дубликати, те ще трябва да бъдат елиминирани. Това също може да стане по няколко начина, но всеки конкретен случай изисква собствен метод и е възможно да се наложи да използвате всички.
Страниците за копиране могат да бъдат изтрити ръчно, но този метод е по-вероятно да е подходящ само за тези дубликати, които са създадени ръчно поради небрежността на уеб администратора.
Пренасочването 301 е чудесно за обединяване на копирани страници, чиито URL адреси се различават по наличието и отсъствието на www.
Решението на проблема с дубликати с помощта на каноничния етикет може да се използва за неясни копия. Например за продуктови категории в онлайн магазин, които имат дубликати, които се различават в сортирането по различни параметри. Canonical е подходящ и за печатни версии на страници и други подобни случаи. Прилага се съвсем просто - атрибутът rel=”canonical” е посочен за всички копия, но не и за главната страница, която е най-подходяща. Кодът трябва да изглежда по следния начин: връзка rel="canonical" href="http://yoursite.ru/stranica-kopiya"/ и да е в тага head.
Настройването на файла robots.txt може да помогне в борбата с дубликатите. Директивата Disallow ще блокира достъпа до дубликати за роботи за търсене. Можете да прочетете повече за синтаксиса на този файл в брой 64 на нашия бюлетин.
заключения
Ако потребителите възприемат дубликатите като една страница с различни адреси, то за паяците това са различни страници с дублирано съдържание. Страниците за копиране са един от най-честите капани, които начинаещите не могат да заобиколят. Тяхното присъствие в големи количества на рекламиран сайт е неприемливо, тъй като те създават сериозни пречки за достигане до ТОП.