Видове компресиране на данни. Компресия. Необходимо ли е в наше време? Кога е необходимо компресиране на данни?
Много потребители днес са загрижени за процеса на компресиране на информация, за да спестят свободно място на твърдия си диск. Този е един от най ефективни начиниизползване на полезно пространство за съхранение.
Съвременните потребители доста често се сблъскват с проблема с липсата на свободно място на твърдия диск. Мнозина, в опит да освободят поне малко свободно място, се опитват да изтрият харддискцялата ненужна информация. По-напредналите потребители използват специални алгоритми за компресиране, за да намалят количеството данни. Въпреки ефективността на този процес, много потребители дори не са чували за него. Нека се опитаме да разберем какво се има предвид под компресиране на данни, какви алгоритми могат да се използват за това и какви предимства предоставя всеки от тях.
Защо да компресирате информация?
Днес компресирането на информация е доста важна процедура, необходима за всеки потребител на компютър. Днес всеки потребител може да си позволи да закупи модерно устройство за съхранение на данни, което осигурява възможност за използване на голямо количество памет. Такива устройства обикновено са оборудвани с високоскоростни канали за излъчване на информация. Въпреки това, заслужава да се отбележи, че всяка година обемът необходими за потребителитеима все повече и повече информация. Само преди десет години размерът на стандартния видео филм не надвишаваше 700 мегабайта. Днес обемът на филмите с HD качество може да достигне няколко десетки гигабайта.
Кога е необходимо компресиране на данни?
Не трябва да очаквате много от процеса на компресиране на информация. Но все още има ситуации, в които компресирането на информация е просто необходимо и изключително полезно. Нека да разгледаме някои от тези случаи.
1. Трансфер от електронна поща.
Много често има ситуации, когато трябва да изпратите голямо количество данни по имейл. Благодарение на компресията можете значително да намалите размера прехвърлени файлове. Тези потребители, които използват мобилни устройства за изпращане на информация, ще оценят особено предимствата на тази процедура.
2. Публикуване на данни в уебсайтове и портали.
Процедурата за компресиране често се използва за намаляване на обема на документите, използвани за публикуване в различни интернет ресурси. Това ви позволява значително да спестите трафик.
3. Спестявания свободно пространствона диск.
Когато не е възможно да добавите нови средства за съхраняване на информация към системата, можете да използвате процедурата за компресиране, за да спестите свободно дисково пространство. Случва се бюджетът на потребителя да е изключително ограничен и на твърдия диск няма достатъчно свободно място. Тук на помощ идва процедурата за компресия.
В допълнение към ситуациите, изброени по-горе, все още има огромен брой случаи, в които процесът на компресиране на данни може да бъде много полезен. Изброили сме само най-често срещаните.
Методи за компресиране на информация
всичко съществуващи методиКомпресирането на информация може да бъде разделено на две основни категории. Това са компресия без загуба и компресия без загуба. Първата категория е от значение само когато има нужда от възстановяване на данни висока точностбез загуба на нито един бит от оригиналната информация. Единственият случай, в който е необходимо да се използва този подход, е компресията текстови документи.
В случай, че няма особена необходимост от най-точното възстановяване на компресирана информация, е необходимо да се предвиди възможността за използване на алгоритми с определени загуби на компресия. Основното предимство на алгоритмите за компресия със загуби е тяхната лекота на внедряване. Също така, такива алгоритми осигуряват доста високо съотношение на компресия.
Компресия със загуби
Алгоритмите за компресия със загуба осигуряват по-добро компресиране на файлове, като същевременно запазват достатъчно информация за възстановяване. Използването на такива алгоритми в повечето случаи е подходящо за компресиране на аналогови данни, като звуци или изображения. В такива случаи крайният резултат може да се различава значително от оригинала. Човек без специално оборудване обаче дори няма да забележи тази разлика.
Компресия без загуба на информация
Алгоритмите за компресиране без загуби позволяват най-точното възстановяване на оригиналните данни. Всякакви загуби са изключени. Въпреки това, този методИма един съществен недостатък: когато се използват такива алгоритми, компресията не е много ефективна.
Универсални методи
Съществуват и специални методи, които могат да се използват за компресиране на информация, съхранявана на твърди дискове, за да се намали нейният размер. Това са така наречените универсални методи. Могат да се разграничат общо три технологии.
1. Преобразуване на потока.
Описанието на входящата некомпресирана информация се извършва чрез файлове, които вече са конвертирани. В този процес не се изчисляват никакви вероятности. Кодирането на знаци се извършва само въз основа на тези файлове, които вече са били подложени на процес на обработка.
2. Статистическа компресия.
Този тип процес на компресиране на информация може да бъде разделен на още два типа: блокови методи и адаптивни методи. Когато се използват блокови алгоритми, всеки отделен блок информация се изчислява отделно и се добавя към блока, който вече е бил компресиран. Адаптивните алгоритми включват изчисляване на вероятности въз основа на информация, която вече е била обработена по време на процеса на компресиране. Този тип метод включва адаптивния алгоритъм на Шанън-Фано.
3. Блокова трансформация.
По време на процеса на компресиране цялата преобразувана информация се разпределя в няколко отделни блока. Има холистична трансформация на информацията.
Трябва да се отбележи, че някои методи, особено тези, които се основават на пренареждане на няколко блока, могат да доведат до намаляване на количеството информация, съхранявана на диска. Основното нещо е да разберете, че след обработка структурата на информацията, съхранявана на диска, се подобрява и оптимизира. В резултат на това последващото компресиране с други методи и алгоритми ще бъде по-лесно и по-бързо.
Компресиране на информация при копиране
Един от най-важните компоненти в изпълнението Резервно копиеинформация е устройството, на което информацията ще бъде прехвърлена. Колкото по-голям обем информация ви е необходим, толкова по-голямо устройство ще трябва да използвате. Проблемът с липсата на свободно пространство може да бъде решен чрез използване на процеса на компресиране на информация.
Когато извършвате архивиране, компресирането на данни може значително да намали времето, което потребителят прекарва в копиране на необходимата информация. Това също позволява по-ефективно използване на свободното пространство на сменяеми носители. При извършване на процедурата за компресиране, копираната информация ще бъде поставена на преносим носител по-бързо и по-компактно.
Това ще ви спести парите, необходими за закупуване на по-голям диск. Освен това, като подлагате информацията, от която се нуждаете, на допълнително компресиране, вие намалявате времето, прекарано за транспортиране на използваните данни до сървъра. Същото важи и за копирането на информация по мрежата. За целите на архивирането информацията може да бъде компресирана в един или повече файлове.
Всичко ще зависи само от програмата, която използвате за компресиране на информацията. Когато избирате помощна програма за компресиране, не забравяйте да обърнете внимание на това как избраната от вас програма може да компресира данни. Ефективността на компресирането също ще зависи от вида на информацията, която конвертирате. Например ефективността на компресия на текстови файлове и документи може да достигне 90%. Но при компресиране на изображения е възможно да се постигне ефективност само от няколко процента.
Заключение
Днес, в ерата на информацията, въпреки факта, че почти всеки потребител има достъп до високоскоростни канали за предаване на данни и медии големи обеми, въпросът за компресирането на данни остава актуален. Има ситуации, в които компресирането на данни е просто необходима операция. По-специално, това се отнася за изпращане на данни по имейл и публикуване на информация в Интернет.
АРХИВАТОРИ
Компресиране на информацияе процесът на трансформиране на информация, съхранена във файл, чрез намаляване на излишъка на данни. Целта на този процес е да се намали обемът, зает от данни.
Архив файле специално създаден файл, съдържащ един или повече файлове в компресирана форма.
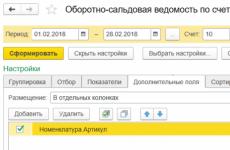
Съотношение на компресия: K c =V c /V o *100%
K c– степен на компресия, Vc- сила на звука компресиран файл, V o– начален размер на файла.
Степента на компресия зависи от:
1) използваната програма - архиватор,
2) метод на компресия,
3) вид на изходния файл: текст, графика, видео, звук и др.
Програмите, които опаковат и разопаковат файлове, се наричат архиватори. Най-често срещаните са: ARJ, ZIP, RAR. Разширението на архивните файлове съвпада с името на архиватора, използван за създаването им.
Архиваторите ви позволяват да създавате саморазархивиращи се архивни файлове, т.е. За да ги разопаковате, не е необходимо да стартирате програмата за архивиране, защото самите те съдържат програма за разопаковане. Тези архиви се наричат SFX архиви
(самоизвличащ се). Разширението на такива файлове е *.EXE.
Принципи на компресиране на информация
Във всеки текст има повтарящи се знаци. Възможно е да се посочи един знак и брой повторения. Ефективността на този алгоритъм е още по-висока, когато се прилага към графични файлове. Ако погледнете монитора, можете да видите много повтарящи се точки от един и същи цвят. Форматът се основава на този принцип на компресиране на информация. графични файлове PCX. Съвременните архиватори подчертават не само повтарящи се знаци, но и вериги от знаци и отделни думи.
Ако текстът не използва всички знаци от компютърната азбука, тогава за кодирането им можете да използвате един байт, 8 бита или по-малко число. Този принцип се използва в телеграфния апарат, където се използват само руснаци главни букви, 5 бита са достатъчни, за да ги представят, което ви позволява да запишете три знака в два байта.
3. Следният принцип използва шаблона, с който се срещат буквите в текста различни честоти. Например в този текст интервалът е най-често срещаният знак, символите "а" и "и" са много често срещани. Тези често срещани знаци могат да бъдат представени като кратка последователност от битове, докато други знаци могат да бъдат кодирани като по-дълга последователност. Например:
4. Физически компютърът разпределя място за поставяне на файлове на диска в клъстери - в блокове от 4 kB. Невъзможно е да се подчертае по-малко. Например, ако даден файл е с размер 8193 байта (8 kB и 1 байт), той физически ще заема 16 kB или 16384 байта. Комбинирането на група файлове в един ви позволява да спестите от тези остатъци. Това осигурява големи спестявания при опаковане на малки файлове.
Общо при отделно поставяне на файлове не се използват 6 kB, което е 100% от съдържанието на файловете. Във втория случай остават неизползвани 2 kB, 33%.
Архиватор zip
Опаковане на файлове pkzip [ключове]<имя архива>[пътища на файлове]
Ключове: -rpархивиране с поддиректории при запазване на структурата
С P.W.D.архивна защита с парола (PWD)
A добавяне на файлове към архива
M преместване на файлове в архив
V преглед на съдържанието на архива
Ако всички файлове в една директория се архивират, тогава е необходимо да се посочи маската *.*
Разопаковане на pkunzip файлове [превключватели]<имя архива>[имена на файлове]
Ключове: -d разопаковане с поддиректории при запазване на структурата
SPWD парола за архив (PWD)
Архиватор arj
арж<команда>[ключове]<имя архива>[имена на файлове]
За архиватора arj един файл извършва както операции по разопаковане, така и по пакетиране.
Отбори: аархивиране
e разопаковане без запазване на структурата на директорията
хразопаковане при запазване на структурата
l преглед на съдържанието на архива
m преместване на файлове в архив
d изтриване на файлове от архива
Ключове: -r опаковане с поддиректории при запазване на структурата
V разбивка на архива на томове с обем vol (ако е посочен)
размерът на стандартните дискети (360, 720, 1200, 1440) е посочен в килобайти, размерът на нестандартните дискети е посочен в байтове
V се посочва при разопаковане на многотомен архив
Ж P.W.D.парола за архив ( P.W.D.)
Опаковане на файлове
Разопаковане на файлове
©2015-2019 сайт
Всички права принадлежат на техните автори. Този сайт не претендира за авторство, но предоставя безплатно използване.
Дата на създаване на страницата: 2016-08-08
Разработването на алгоритми за компресиране на информация принадлежи към един от клоновете на приложната математика. Те се основават на принципа на елиминиране на естествената излишност.
Методите за компресиране на информация условно се разделят на два неприпокриващи се класа: компресия със загубиИ компресия без загуба на информация.
Компресия със загубиозначава, че след разопаковане на компресирания архив, получените данни са малко по-различни от това, което е било в самото начало. Очевидно, колкото по-високо е съотношението на компресия, толкова по-големи са загубите и обратно.
Разбира се, такива алгоритми не са приложими за текстови документи, таблици от бази данни и програми. Незначителните изкривявания в прост неформатиран текст все още могат да бъдат преживени по някакъв начин, но изкривяването дори на един бит в програмата ще я направи напълно неработеща.
В същото време има данни, в които можете да пожертвате няколко процента от информацията, за да получите компресия десетки пъти, например снимки, видео и аудио материали. Загубата на информация по време на компресиране и последващо декомпресиране на такива данни се възприема като появата на някакъв допълнителен „шум“.
Алгоритмите за компресия със загуби включват алгоритми като JPEG(използва се при компресиране на фото изображения) и MPEG(използва се за видео и аудио компресия). Алгоритмите за компресия със загуби се използват само за потребителски задачи.
Размерът на допустимата загуба на компресия обикновено може да се контролира, което позволява постигането на оптимално съотношение размер/качество. При фотографски илюстрации, предназначени за възпроизвеждане на екрана, загубата на 5% от информацията обикновено не е критична, а в някои случаи може да се толерира загуба на 20-25%.
Методи компресия без загуба на информациясе използват при работа с текстови документи и програми и не могат да допуснат загуба на информация. Те се основават само на премахване на неговата излишност.
Пример 1. Украинският език има 32 букви, десет цифри и около дузина препинателни знаци и други специални знаци. Само за текст, който е написан с главни букви(както в телеграмите) шестдесет биха били достатъчни различни значения. Всеки символ обаче обикновено се кодира от байт, който съдържа 8 бита и може да изрази 256 различни кода. Това е първата причина за съкращаване. За „телеграфен“ текст биха били достатъчни шест бита на знак.
Ориз. 1. Морзова азбука
Пример 2. В международното ASCII кодиране на знаци, същият брой битове (8) се разпределят за кодиране на всеки знак. В същото време е очевидно, че има смисъл да се кодират най-често срещаните знаци с по-малко знаци. Така, например, в морзов кодбуквите “E” и “T”, които се срещат често, са кодирани с един знак (съответно точка и тире). И такива редки букви като "Yu" (--) и "C" (- -) са кодирани с четири знака. Неефективното кодиране е втората причина за излишъка.
Програмите, които извършват компресиране на информация, могат да въведат свое собствено кодиране (различно за различни файлове) и прикачете определена таблица (речник) към компресирания файл, от която програмата за разопаковане научава как да този файлопределени знаци или техните групи са кодирани. Наричат се алгоритми, базирани на прекодиране на информация Алгоритми на Хъфман.
Наличието на повтарящи се фрагменти е третото основание за излишък. Това е рядко в текстовете, но в таблиците и графиките повторението на кодовете е често срещано. Така например, ако числото 0 се повтаря двадесет пъти подред, тогава няма смисъл да се поставят двадесет нула байта. Вместо това те поставят една нула и коефициент 20. Такива алгоритми, базирани на идентифициране на повторения, се наричат методи кодиране на дължина на изпълнение(RLE,Кодиране на дължината на цикъла). Графичните илюстрации се отличават особено с големи повтарящи се последователности от идентични байтове. Методът е доста ефективен за графични изображениявъв формат байт на пиксел (например формати PCXили BMP).
Докато създавате резервни копияПри твърдите дискове има още една възможност за получаване на работно пространство при компресиране на файлове, което не е свързано с излишната информация, а с начина, по който е организирана файловата система на компютъра. Същността му се състои в това, че всеки файл, голям или малък, може да заема само цял брой клъстери на диска. IN файлова система FAT16 на твърд диск не може да има повече от 65536 клъстера (2 16). Това означава, че за дискове с размер от 1 до 2 GB, размерът на клъстера е 32 KB.
При компактиране на голяма група файлове в един файл спестяванията възлизат на поне 16 KB на файл само чрез намаляване на загубите от нерационалната организация на файловата система.
За FAT32 печалбата е по-малка, но в този случай минималният размер на клъстера е 4 KB, така че ако имате работа с голяма сумамалки файлове, тогава има и какво да запазите тук.
Въпреки че има много различни методи за компресиране, има някои принципи и правила, които са общи за всички методи за компресиране. Те трябва да се познават и използват правилно.
1. Всяка компресия има ограничение,тези. Компактирането на предварително компресиран файл в най-добрия случай не осигурява никаква печалба, а в най-лошия случай може да доведе до загуба на размера на получения файл.
Архив - Компресиране на файлове: Как става това? - Компютърно списаниеЗдравейте! Бихте ли обяснили на начинаещ потребител как се компресират файлове от различни архиватори? Поне в общи линии. Иначе ми е трудно да си представя как би могло да стане това.
Виталий
Абсолютно правилно, Виталий, наистина не е толкова лесно да си представите, особено ако не знаете алгоритъма. Но читателите на списание Computer са късметлии ;), защото по едно време много се интересувах от алгоритми за компресиране на данни и като програмист дори се опитах да напиша собствен архиватор.
Компресирането на данни е алгоритмична трансформация на данни, извършена с цел намаляване на техния обем. Използва се за по-рационално използване на устройствата за съхранение и предаване на данни. Процесът на компресиране се нарича още пакетиране на данни или компресия. Обратната процедура се нарича възстановяване на данни (разопаковане, декомпресия).
Компресията се основава на елиминиране на излишъка, съдържащ се в оригиналните данни. Най-простият пример за излишък е повторението на фрагменти в текста (например думи на естествен или машинен език).
Така че нека започнем с прост пример. Да кажем, че имаме текстов файл, който съдържа ред текст:
AAAGGDEEEEZHJUUUUUKKKKKKKKKK
Текстът е доста странен, ще се съгласите, но сега ще го компресираме и ще заема по-малко място. Основният принцип на компресията е много прост и се свежда до следното: всяка комбинация от последователно повтарящи се знаци се заменя с един такъв знак и броя на неговите повторения. Тези. нашият компресиран изходен текст ще изглежда така:
A3G2D1E4ZH2U3K4I3
Така вместо 22 символа получихме 16 знака. Разбира се, текстове като оригиналния ни са доста редки, да не говорим за глупостите, които се съдържат в него. Но файловете, които се подлагат на компресиране, не са само текстови файлове, но и всички видове снимки, музика, видеоклипове и програми.
Този пример е доста опростен и не отразява ефективността, която архиваторите обикновено демонстрират при компресиране. Така че имаме компресия от 22/16 = 1,375 пъти, въпреки че архиваторите, като правило, са в състояние да компресират файлове от 2-10 000 пъти. Всичко зависи от повторяемостта на байтовите стойности във файла.
Какви видове архиватори има?
Например, по време на незабравимия MS-DOS имаше архиватори ARJ, PKZIP, HA, RAR, ARC, ACE и пакетиращи програми LZEXE и PKLITE. По-късно за операционна система Windows са създадени от WinAce, WinZIP, WinRAR, 7Zip и пакета UPX, който познавам.
Компресията може да бъде със или без загуби. Компресията без загуби ви позволява да възстановите оригиналните данни с точност бит по бит. Това компресиране се използва за опаковане на текст, програми и различни данни в отделение и се извършва от всички изброени по-горе архиватори.
Компресията със загуби може да се нарече адаптивна компресия и се използва за опаковане на изображения, видео и звук, тъй като такива данни могат да бъдат компресирани без много малка загуба (само до около 2 пъти).
Благодарение на компресията със загуби е възможно да се постигне многократно намаляване на количеството данни, а при показване на декомпресирани данни човек едва ли ще усети разликата между оригинала.
Колко са компресирани различните файлове?
Текст
Всъщност, например, текстовите файлове могат да бъдат компресирани много плътно. Така например книгата „Трудно е да бъдеш бог“ от Аркадий и Борис Стругацки с размер 354 329 байта е компресирана от архиватора WinRAR до 140 146 байта, т.е. 2,5 пъти.
Програми
Програмните файлове също могат да бъдат компресирани. В същото време компресията се използва както за по-плътно съхранение на диска, така и за компресия, при която програмата остава програма, но се декомпресира при стартиране.
За целта има програми за пакетиране на програми като UPX и други, например моят текстов редактор Superpad.exe, с размер 524 288 байта, е компресиран от пакета UPX до 179 200 байта (2,9 пъти) и все още може да работи независимо като програма.
Изображения
Цяла статия или дори повече от една може да бъде посветена на описанието на методите за компресиране на тези данни. Факт е, че самото изображение се компресира много лошо, ако се компресира байт по байт. И все пак успява. Особено ако картината има много обикновен фон.
Един от първите алгоритми за компресиране на изображения беше алгоритъмът RLE, който описах по-горе. Използва се във формата за съхранение на изображения PCX. RLE е алгоритъм за компресия без загуби. Но в някои случаи може да доведе не до намаляване на количеството данни, а до неговото увеличаване.
Следователно алгоритъмът за побитово компресиране на LZW беше предложен и все още се използва за компресиране на изображения. Самият алгоритъм е много по-ефективен от RLE и също така не предвижда загуби. Но тъй като се използва за изображения с цветова палитра, чрез адаптиране и оптимизиране (компресиране) на палитрата може да се постигне значително повишаване на ефективността на компресията.
Ориз. 1. Красива жаба в BMP формат
За сравнение, нека вземем красива жаба (фиг. 1) с разделителна способност 799x599 пиксела (точки) и да я запазим в различни формати за съхранение на изображения. Да вземем файловете:
frog.bmp - размер 1 437 654 байта и тук всъщност няма компресия и загуба на качество, тъй като изображението заема зададените му байтове във формат Ширина х Височина х 3 байта на пиксел + заглавка на BMP файлов формат според Качество на истинските цветове (24 бита/пиксел). Тези. всяка точка е представена от три RGB компонента (червен, зелен и син), всеки от които заема един байт.
frog24.png - 617 059 байта, 2,33 пъти компресия и без загуба - основното свойство на формата PNG-24. BMP и PNG данните са почти идентични.
Ориз. 2. Файл frog_256colors.gif
frog_256colors.gif - 261 956 байта (фиг. 2), 5,48 пъти компресия със загуби, основна палитра 256 цвята (8 бита/пиксел). Доста трудно е да се направи разлика между този файл и оригинала в BMP, като в онази игра „Намерете десетте разлики“.
Ориз. 3. Файл frog_64colors.gif
frog_64colors.gif - 187 473 байта (фиг. 3), 7,67 пъти компресия със загуби, базова палитра е компресирана до 64 цвята (6 бита/пиксел). И тук цветовете вече са избелели, но изображението е доста подобно на оригинала. Това е особено забележимо, ако погледнете окото на жабата.
JPEG
Заема специално място в компресирането и съхранението на изображения JPEG формат. Затова искам да му обърна специално внимание. JPEG алгоритъмнай-подходящ за компресиране на снимки и картини, съдържащи реалистични сцени с плавни преходияркост и цвят. JPEG се използва най-широко в цифровата фотография и за съхраняване и предаване на изображения чрез интернет.
От друга страна, JPEG е неподходящ за компресиране на рисунки, текст и символни графики, където резкият контраст между съседни пиксели води до забележими артефакти. Препоръчително е да запазвате такива изображения във формати без загуби като TIFF, GIF, PNG или RAW.
JPEG (подобно на други методи за компресиране на изкривяване) не е подходящ за компресиране на изображения по време на многоетапна обработка, тъй като ще се внасят изкривявания в изображенията всеки път, когато се записват междинни резултати от обработката.
JPEG не трябва да се използва в случаите, когато дори минимални загуби са неприемливи, например при компресиране на астрономически или медицински изображения. В такива случаи може да се препоръча режимът за компресиране на JPEG без загуби, осигурен от стандарта JPEG (който, за съжаление, не се поддържа от повечето популярни кодеци) или стандартът за компресия JPEG-LS.
Описанието на алгоритъма за компресиране на JPEG е доста сложно, така че всеки, който иска, може да го прочете на http://el-izdanie.narod.ru/gl4/4-3.htm. Е, за сравнение, нека компресираме нашето оригинално изображение с различни нивакачества:
frog100%.jpg - 216 168 байта, компресия 6,65 пъти, уж 0% загуба, т.е. 100% качество на картината, но дори не бих разчитал на това. Повярвайте ми, има разлики, макар че те са абсолютно неразличими за окото.
frog60%.jpg - 85 910 байта, компресия 16,7 пъти, т.е. качеството на картината е 60%, но картината отново изглежда същата, въпреки че ако се вгледате внимателно в области с равномерен фон или малки детайли, ще забележите артефакти под формата на замъгляване или квадратни монохромни сегменти.
frog20%.jpg - 36 426 байта, компресия 39,5 пъти, качество на картината 20% от оригиналното изображение, но въпреки това картината все още може да измами нетренираното око, но на еднороден фон ясно се виждат едноцветни ъглови сегменти и малките детайли са напълно изгубени ясните си очертания.
MPEG
Това е един от най-ранните и най-често срещаните формати за съхранение на видео. Модернизирана няколко пъти. Но в опростена форма можем да кажем, че алгоритъмът е много подобен на компресията като в JPEG, но като вземем предвид факта, че първият кадър на видеото винаги е оригиналът и оригиналът, а следващите кадри съхраняват само разликата между предишни и следващи кадри. Благодарение на това всеки следващ кадър е предвидим от гледна точка на декомпресия (фиг. 4 и 5).

Ориз. 4. Оригинални видео рамки

Ориз. 5. Междукадрова разлика без използване на алгоритми за компенсация на движението
Една от най-мощните технологии за увеличаване на степента на компресия е компенсацията на движението. За всякакви модерна системавидео компресия, следващите кадри в потока използват сходството на области в предишни кадри, за да увеличат коефициента на компресия.
Въпреки това, поради движението на всякакви обекти в кадъра (или самата камера), използването на прилика между съседни кадри беше непълно. Технологията за компенсиране на движението ви позволява да намерите подобни области, дори ако те са изместени спрямо предишния кадър.
Компенсацията на движение е един от основните алгоритми, използвани при обработката и компресирането на видео данни. Алгоритъмът използва сходството на съседни кадри във видео поредица и намира вектори на движение отделни частиизображения (обикновено 16x16 и 8x8 блокове).
Използването на компенсация позволява компресията да се увеличи многократно чрез премахване на излишъка под формата на съвпадащи части от кадри. Използва се не само за компресиране, но и за филтриране на видео, промяна на честотата на кадрите и др.
В почти всяко видео съседните кадри са подобни, имат общи обекти, които като правило се изместват един спрямо друг. И е напълно естествено да искате да кодирате видеото така, че обектите да не се кодират многократно, а просто да се описват някои от техните премествания.
В същото време изображението е разделено на така наречените ключови кадри - това са групи от кадри, които се изпълняват подред за няколко секунди. Чрез контролиране на продължителността на такива ключови кадри, компресията може да бъде ефективно контролирана.
Например, ако сюжетът на филма не е динамичен, тогава продължителността на ключовите кадри може да бъде няколко секунди. Ако филмът съдържа динамични сцени, тогава в такива моменти продължителността на ключовите кадри може да бъде намалена и компресията на бързо променящо се изображение ще бъде по-ефективна.
Ключовите кадри също така опростяват и ускоряват пренавиването в мултимедийните плейъри, тъй като заглавката на всеки ключов кадър съдържа връзка (отместване в байта спрямо началото на видео файла) към началото на следващия ключов кадър.
Звук и музика
Звукът и музиката могат да бъдат без загуба или със загуба, съхранени във формат WAV. Например форматът WAV (Windows PCM) не осигурява компресия и съхранява аудио сигнала в оригинал, така да се каже.
Форматът WAV (ACM Waveform) е по същество контейнер и може да съхранява аудио, компресирано с помощта на алгоритъма MPEG слой 3, или да съхранява музика в MP3 формат, въпреки че има много други формати OGG, FLAC и др.
Нямам време да говоря за алгоритми за аудио компресия, освен това по-рано в нашето списание имаше чудесна статия по тази тема.
Методите за компресиране на данни имат доста дълга история на развитие, която започва много преди появата на първия компютър. Тази статия ще се опита да направи кратък преглед на основните теории, концепции за идеи и техните реализации, без обаче да претендира за абсолютна пълнота. По-подробна информация можете да намерите например в Krichevsky R.E. , Рябко Б.Я. Witten I.H. , Rissanen J., Huffman D.A., Gallager R.G. , Кнут Д.Е. , Vitter J.S. и т.н.
Компресирането на информация е проблем, който има доста дълга история, много по-дълга от историята на развитието на компютърните технологии, която (историята) обикновено върви успоредно с историята на развитието на проблема за кодиране и криптиране на информация. Всички алгоритми за компресиране работят върху входен поток от информация, чиято минимална единица е бит, а максималната единица е няколко бита, байта или няколко байта. Целта на процеса на компресиране, като правило, е да се получи по-компактен изходен поток от информационни единици от някакъв първоначално некомпактен входен поток чрез някаква трансформация. Основните технически характеристики на компресионните процеси и резултатите от тяхната работа са:
Степента на компресия (компресия) или съотношението (съотношението) на обемите на оригиналния и получения поток;
Степен на компресия - времето, изразходвано за компресиране на определено количество информация от входен поток, преди да се получи еквивалентен изходен поток от него;
Качеството на компресията е стойност, която показва колко плътно е компресиран изходният поток чрез прилагане на повторна компресия към него, използвайки същия или друг алгоритъм.
Има няколко различни подхода към проблема с компресирането на информацията. Някои имат много сложна теоретична математическа основа, други се основават на свойствата на информационния поток и са алгоритмично доста прости. Всеки подход и алгоритъм, който прилага компресия на данни или компресия, е предназначен да намали обема на изходния информационен поток в битове, като използва неговата обратима или необратима трансформация. Следователно, на първо място, според критерия, свързан с естеството или формата на данните, всички методи за компресиране могат да бъдат разделени на две категории: обратимо и необратимо компресиране.
Необратимо компресиране означава такова преобразуване на входния поток от данни, при което изходният поток, базиран на определен информационен формат, представлява от определена гледна точка обект, доста подобен по външни характеристики на входния поток, но се различава от него по сила на звука. Степента на сходство между входните и изходните потоци се определя от степента на съответствие на определени свойства на обекта (т.е. компресирана и некомпресирана информация, в съответствие с някакъв специфичен формат на данни), представен от даден информационен поток. Такива подходи и алгоритми се използват за компресиране например на данни от растерни графични файлове с ниска степен на повторение на байтовете в потока. Този подход използва структурното свойство на графичния файлов формат и способността да се представи графично изображение с приблизително подобно качество на дисплея (за възприемане от човешкото око) по няколко (или по-скоро n) начина. Следователно, в допълнение към степента или големината на компресия, понятието качество възниква в такива алгоритми, т.к. Тъй като оригиналното изображение се променя по време на процеса на компресиране, качеството може да се разбира като степента на съответствие между оригиналните и получените изображения, оценени субективно въз основа на информационния формат. За графичните файлове това съответствие се определя визуално, въпреки че има и съответните интелигентни алгоритми и програми. Необратимата компресия не може да се използва в области, където е необходимо да има точно съвпадение между информационната структура на входния и изходния поток. Този подход се прилага в популярни формати за представяне на видео и фото информация, известни като JPEG и JFIF алгоритми и JPG и JIF файлови формати.
Обратимата компресия винаги води до намаляване на обема на изходния информационен поток, без да се променя неговото информационно съдържание, т.е. - без загуба на информационна структура. Освен това от изходния поток, използвайки алгоритъм за реконструкция или декомпресия, може да се получи входът и процесът на възстановяване се нарича декомпресия или декомпресия и едва след процеса на декомпресия данните са подходящи за обработка в съответствие с вътрешния им формат.
При обратимите алгоритми кодирането като процес може да се разглежда от статистическа гледна точка, което е още по-полезно не само за конструиране на алгоритми за компресиране, но и за оценка на тяхната ефективност. За всички обратими алгоритми има понятие за цена на кодиране. Разходите за кодиране се отнасят до средната дължина на кодова дума в битове. Излишъкът на кодиране е равен на разликата между цената и ентропията на кодирането и добрият алгоритъм за компресиране трябва винаги да минимизира излишъка (не забравяйте, че ентропията на информацията е мярката за нейното разстройство). Фундаменталната теорема на Шанън за кодирането на информация казва, че „цената на кодирането винаги е не по-малка от ентропията на източника, въпреки че може да бъде произволно близка до нея.“ Следователно за всеки алгоритъм винаги има определена граница на степента на компресия, определена от ентропията на входния поток.
Нека сега преминем директно към алгоритмичните характеристики на обратимите алгоритми и да разгледаме най-важните теоретични подходи за компресиране на данни, свързани с внедряването на системи за кодиране и методи за компресиране на информация.
Компресиране чрез метод на серийно кодиране
Най-известният прост подход и алгоритъм за компресиране на информация по обратим начин е Run Length Encoding (RLE). Същността на методите при този подход е да заменят вериги или серии от повтарящи се байтове или техните последователности с един кодиращ байт и брояч за броя на техните повторения. Проблемът с всички подобни методи е само да се определи начинът, по който декомпресиращият алгоритъм може да различи кодирана серия от други некодирани последователности от байтове в резултантния поток от байтове. Решението на проблема обикновено се постига чрез поставяне на знаци в началото на кодираните вериги. Такива етикети могат да бъдат напр. характерни стойностибитове в първия байт на кодираната серия, стойността на първия байт на кодираната серия и т.н. Тези методи, като правило, са доста ефективни за компресиране на растерна графика (BMP, PCX, TIF, GIF), т.к. последните съдържат доста дълги серии от повтарящи се последователности от байтове. Недостатъкът на метода RLE е доста ниското съотношение на компресия или цената на кодиране на файлове с малък брой серии и, още по-лошо, с малък брой повтарящи се байтове в серията.
Компресия без използване на метода RLE
Процесът на компресиране на данни без използване на метода RLE може да бъде разделен на два етапа: моделиране и всъщност кодиране. Тези процеси и алгоритмите за тяхното изпълнение са доста независими и разнообразни.
Процес на кодиране и неговите методи
Кодирането обикновено означава обработка на поток от символи (в нашия случай байтове или хапки) в някаква азбука, като честотите на появяване на символи в потока са различни. Целта на кодирането е да преобразува този поток в поток от битове с минимална дължина, което се постига чрез намаляване на ентропията на входния поток чрез отчитане на честотите на символите. Дължината на кода, представляващ символи от азбуката на потока, трябва да бъде пропорционална на количеството информация във входния поток, а дължината на символите на потока в битове не може да бъде кратна на 8 или дори променлива. Ако е известно вероятностното разпределение на честотите на поява на символи от азбуката на входния поток, тогава може да се изгради оптимален модел на кодиране. Въпреки това, поради наличието на огромен брой различни файлови формати, задачата става много по-сложна. Честотното разпределение на символите с данни е неизвестно предварително. В този случай, в общ изглед, се използват два подхода.
Първият е да видите входния поток и да конструирате кодиране въз основа на събраната статистика (това изисква две преминавания през файла - едно за преглед и събиране на статистическа информация, второ за кодиране, което донякъде ограничава обхвата на такива алгоритми, тъй като, по този начин елиминира възможността за кодиране с едно преминаване в движение, използвано в телекомуникационни системи, където обемът на данните понякога е неизвестен и тяхното повторно предаване или анализиране може да отнеме неоправдано дълго време). В този случай статистическата схема на използваното кодиране се записва в изходния поток. Този метод е известен като статично кодиране на Хъфман.
|
|