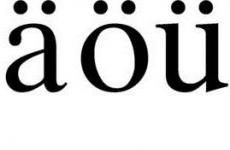Базовые понятия реляционной модели данных - файл Базовые понятия реляционной модели данных.doc. Как проектируют базы данных. Основные концепции реляционных баз данных
Раздел 3. «Базы данных»
1. Информационное обеспечение автоматизированных систем.
Информационное обеспече’ние автоматизированной системы (АС) - совокупность форм документов, классификаторов, нормативной базы и реализованных решений по объемам, размещению и формам существования информации, применяемой в АС при ее функционировании
По ГОСТ 24.205-80 описание информационного обеспечения АСУ должно состоять из следующих разделов:
принципы организации информационного обеспечения;
организация сбора и передачи информации;
построение системы классификации и кодирования;
организация внутримашинной информационной базы;
организация внемашинной информационной базы.
Термин «информационное обеспечение» широко используется в разном контексте, применительно к разным функциям и видам деятельности, трактуется неоднозначно и является дискуссионным. Кроме обозначения этим термином информационных структур, под этим нередко понимается процесспредоставления необходимой информации для нужд определенного социально-экономического объекта.
Информационное обеспечение сети вычислительных центров включает массивы данных, средства их описания, сбора, хранения и выдачи, которые должны в совокупности создать наилучшие условия для централизованной интегрированной обработки информации, обеспечить коллективный доступ к общим для многих абонентов данным, повысить надёжность и достоверность получаемой информации.
Информационное обеспечение автоматизированной системы – это совокупность форм документов, классификаторов, нормативной базы и реализованных решений по объемам, размещению и формам существования информации, применяемой в автоматизированной системе при ее функционировании (ГОСТ 34.003-90 ("Автоматизированные системы. Термины и определения")).
ИО - совокупность единой системы классификации и кодирования информации, унифицированных систем документации, схем информационных потоков, циркулирующих в организации, методология построения баз данных .
Данная подсистема предназначена для своевременного представления информации, принятия управленческих решений. ИО предприятия представляет собой информационную модель данного объекта. Для создания ИО нужно ясное понимание целей и задач, функций системы управления; совершение системы документооборота; выявление движения информации от момента ее возникновения и до ее использования на различных уровнях управления; наличие и использование классификации и кодирования информации; создание массивов информации на машинных носителях; владение методологией создания информационных моделей .
При организации ИО используется системный подход, обеспечивающий создание единой информационной базы; разработку типовой схемы обмена данными между различными уровнями системы и внутри каждого уровня; организацию единой схемы ведения и хранения информации; обеспечение решаемых задач исходными данными;
Основными функциями ИО являются наблюдение за ходом производственно-хозяйственной деятельности, выявление и регистрация состояния управляемых параметров и их отклонение от заданных режимов; подготовка к обработке первичных документов, отражающих состояние управляемых объектов; обеспечение автоматизированной обработки данных; осуществление прямой и обратной связи между объектами и субъектами управления.
ИО автоматизированных информационных систем состоит из внемашинного и внутри машинного ИО .
Внемашинное включает систему классификации и кодирования технико-экономической информации; систему документации; схему информационных потоков (документооборота: первичные, результативные, нормативно-справочные документы).
Внутримашинное ИО содержит массивы данных на машинных носителях и программу организации доступа к этим данным.
Внемашинное ИО - информация, которая воспринимается человеком без каких-либо технических средств (документы).
Под классификацией понимается условное расчленение множества элементов информации на подмножества на основании сходства или различия по какому-то признаку.
2. СУБД и приложения баз данных.
Система управления базами данных (СУБД) представляет собой комплекс языковых и программных средств, которые обеспечивают управление созданием и использованием баз данных.
Современная СУБД состоит из:
ядра - части программ СУБД, отвечающих за управление данными в памяти и журнализацию; Процессора языка базы данных, обеспечивающего оптимизацию запросов на извлечение и изменение данных, и создание БД;
Подсистемы поддержки времени исполнения, интерпретирующую программы манипуляции данными, которые создают интерфейс пользователя СУБД;
Сервисных программ (внешних утилит), которые обеспечивают прочие возможности по обслуживанию информационных систем.
Основными функциями СУБД являются
Управление данными, хранящимися во внешней памяти;
Управление данными, загруженными в оперативную память с использованием дискового кэша; Журнализация событий и изменений, резервное копирование и восстановление БД после сбоев;
Поддержка языков обращения с БД (язык определения данных, язык манипулирования данными);
Классификации СУБД
Существует несколько признаков, по которым можно классифицировать СУБД.
СУБД по модели данных бывают:
Иерархические СУБД, Сетевые СУБД, Реляционные СУБД, Объектно-ориентированные СУБД, Объектно-реляционные СУБД. В настоящее время в серьезных проекта используются 2 последних типа. СУБД по степени распределённости. Локальные (СУБД размещается только на одном компьютере) Распределённые (части СУБД могут размещаться на 2-х и более компьютерах).
Приложений баз данных
Приложение баз данных, как следует уже из его названия, предназначено для взаимодействия с некоторым источником данных - базой данных (БД). Взаимодействие подразумевает получение данных, их представление в определенном формате для просмотра пользователем, редактирование в соответствии с реализованными в программе бизнес- алгоритмами и возврат обработанных данных обратно в базу данных.
В качестве источника данных могут выступать как собственно базы данных, так и обычные файлы - текстовые, электронные таблицы и т. д. Но здесь мы будем рассматривать приложения, работающие с базами данных.
Само приложение включает механизм получения и отправки данных, механизм внутреннего представления данных в том или ином виде, пользовательский интерфейс для отображения и редактирования данных, бизнес-логику для обработки данных.
Механизм получения и отправки данных обеспечивает соединение с источником данных (часто опосредованно). Он должен "знать", куда ему обращаться и какой протокол обмена использовать для обеспечения двунаправленного потока данных.
Механизм внутреннего представления данных является ядром приложения баз данных. Он обеспечивает хранение полученных данных в приложении и предоставляет их по запросу других частей приложения.
Пользовательский интерфейс обеспечивает просмотр и редактирование данных, а также управление данными и приложением в целом.
Бизнес-логика приложения представляет собой набор реализованных в программе алгоритмов обработки данных.
Между приложением и собственно базой данных находится специальное программное обеспечение (ПО), связывающее программу и источник данных и управляющее процессом обмена данными. Это ПО может быть реализовано самыми разнообразными способами, в зависимости от объема базы данных, решаемых системой задач, числа пользователей, способами соединения приложения и базы данных. Промежуточное ПО может быть реализовано как окружение приложения, без которого оно вообще не будет работать, как набор драйверов и динамических библиотек, к которым обращается приложение, может быть интегрировано в само приложение. Наконец, это может быть отдельный удаленный сервер, обслуживающий тысячи приложений.
Источник данных представляет собой хранилище данных (саму базу данных) и СУБД, управляющую данными, обеспечивающую целостность и непротиворечивость данных.
3. Современная концепция реляционных БД.
Основные концепции реляционных баз данных
Прежде чем подробно рассматривать каждый из этих шагов, остановимся на основных концепциях реляционных баз данных. В реляционной теории одним из главных является понятие отношения. Математически отношение определяется следующим образом. Пусть даны n множеств D1,D2,...,Dn. Тогда R есть отношение над этими множествами, если R есть множество упорядоченных наборов вида
Легко заметить, что отношение является отражением некоторой сущности реального мира (в данном случае - сущности “деталь”) и с точки зрения обработки данных представляет собой таблицу. Кортеж представляет собой строку в таблице, или, что то же самое, запись. Атрибут же является столбцом таблицы, или - полем в записи. Домен же представляется неким обобщенным типом, который может быть источником для типов полей в записи. Таким образом, следующие тройки терминов являются эквивалентными:
отношение, таблица
кортеж, строка, запись
атрибут, столбец, поле.
Реляционная база данных представляет собой совокупность отношений, содержащих всю необходимую информацию и объединенных различными связями.
Атрибут (или набор атрибутов), который может быть использован для однозначной идентификации конкретного кортежа (строки, записи), называется первичным ключом. Первичный ключ не должен иметь дополнительных атрибутов. Это значит, что если из первичного ключа исключить произвольный атрибут, оставшихся атрибутов будет недостаточно для однозначной идентификации отдельных кортежей. Для ускорения доступа по первичному ключу во всех системах управления базами данных (СУБД) имеется механизм, называемый индексированием. Грубо говоря, индекс представляет собой инвертированный древовидный список, указывающий на истинное местоположение записи для каждого первичного ключа. Естественно, в разных СУБД индексы реализованы по-разному (в локальных СУБД - как правило, в виде отдельных файлов), однако, принципы их организации одинаковы.
Возможно индексирование отношения с использованием атрибутов, отличных от первичного ключа. Данный тип индекса называется вторичным индексом и применяется в целях уменьшения времени доступа при нахождении данных в отношении, а также для сортировки. Таким образом, если само отношение не упорядочено каким-либо образом и в нем могут присутствовать строки, оставшиеся после удаления некоторых кортежей, то индекс (для локальных СУБД - индексный файл), напротив, отсортирован.
Для поддержания ссылочной целостности данных во многих СУБД имеется механизм так называемых внешних ключей. Смысл этого механизма состоит в том, что некоему атрибуту (или группе атрибутов) одного отношения назначается ссылка на первичный ключ другого отношения; тем самым закрепляются связи подчиненности между этими отношениями. При этом отношение, на первичный ключ которого ссылается внешний ключ другого отношения, называется master-отношением, или главным отношением; а отношение, от которого исходит ссылка, называется detail-отношением, или подчиненным отношением. После назначения такой ссылки СУБД имеет возможность автоматически отслеживать вопросы “ненарушения“ связей между отношениями, а именно:
если Вы попытаетесь вставить в подчиненную таблицу запись, для внешнего ключа которой не существует соответствия в главной таблице (например, там нет еще записи с таким первичным ключом), СУБД сгенерирует ошибку;
если Вы попытаетесь удалить из главной таблицы запись, на первичный ключ которой имеется хотя бы одна ссылка из подчиненной таблицы, СУБД также сгенерирует ошибку.
если Вы попытаетесь изменить первичный ключ записи главной таблицы, на которую имеется хотя бы одна ссылка из подчиненной таблицы, СУБД также сгенерирует ошибку.
ДОПОЛНЕНИЕ
Базовые понятия реляционных баз данных
Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение.
Тип данных
Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как "деньги"), а также специальных "темпоральных" данных (дата, время, временной интервал). Достаточно активно развивается подход к расширению возможностей реляционных систем абстрактными типами данных (соответствующими возможностями обладают, например, системы семейства Ingres/Postgres). В нашем примере мы имеем дело с данными трех типов: строки символов, целые числа и "деньги".
Домен
Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с подтипами в некоторых языках программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат "истина", то элемент данных является элементом домена.
Наиболее правильной интуитивной трактовкой понятия домена является понимание домена как допустимого потенциального множества значений данного типа. Например, домен "Имена" в нашем примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака).
Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В нашем примере значения доменов "Номера пропусков" и "Номера групп" относятся к типу целых чисел, но не являются сравнимыми. Заметим, что в большинстве реляционных СУБД понятие домена не используется, хотя в Oracle V.7 оно уже поддерживается.
Реляционные базы данных являются наиболее распространенными в настоящее время, хотя наряду с общепризнанными достоинствами обладает и рядом недостатков. К числу достоинств реляционного подхода можно отнести:
Наличие небольшого набора абстракций, которые позволяют сравнительно просто моделировать большую часть распространенных предметных областей и допускают точные формальные определения, оставаясь интуитивно понятными;
Наличие простого и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных;
Возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти.
Реляционные системы далеко не сразу получили широкое распространение. В то время, как основные теоретические результаты в этой области были получены еще в 70-х, и тогда же появились первые прототипы реляционных СУБД, долгое время считалось невозможным добиться эффективной реализации таких систем. Однако отмеченные выше преимущества и постепенное накопление методов и алгоритмов организации реляционных баз данных и управления ими привели к тому, что уже в середине 80-х годов реляционные системы практически вытеснили с мирового рынка ранние СУБД.
В настоящее время основным предметом критики реляционных СУБД является не их недостаточная эффективность, а присущая этим системам некоторая ограниченность (прямое следствие простоты) при использование в так называемых нетрадиционных областях (наиболее распространенными примерами являются системы автоматизации проектирования), в которых требуются предельно сложные структуры данных. Еще одним часто отмечаемым недостатком реляционных баз данных является невозможность адекватного отражения семантики предметной области. Другими словами, возможности представления знаний о семантической специфике предметной области в реляционных системах очень ограничены. Современные исследования в области постреляционных систем главным образом посвящены именно устранению этих недостатков.
Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение.
Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как "деньги"), а также специальных "темпоральных" данных (дата, время, временной интервал). Достаточно активно развивается подход к расширению возможностей реляционных систем абстрактными типами данных (соответствующими возможностями обладают, например, системы семейства Ingres/Postgres).
Структуры данных реляционной модели. Реляционная модель данных организует и представляет данные в виде таблиц или реляций. Реляция – это термин, пришедший из математики и обозначающий простую двумерную таблицу. В реляционном подходе к построению баз данных используется терминология теории отношений. Простейшая двумерная таблица определяется какотношение.
Таблица является основным типом структуры данных (объектом) реляционной модели. Структура таблицы определяется совокупностью столбцов. В каждой строке таблицы содержится по одному значению в соответствующем столбце. В таблице не может быть двух одинаковых строк. Общее число строк не ограничено.
Столбец соответствует некоторому элементу данных –атрибуту, который является простейшей структурой данных. В таблице не могут быть определены множественные элементы, группа или повторяющаяся группа, как в рассмотренных выше сетевых и иерархических моделях. Каждый столбец таблицы должен иметь имя соответствующего элемента данных (атрибута).
Столбец таблицы со значениями соответствующего атрибута называется доменом, а строки со значениями разных атрибутов –кортежем.
Реляционная таблица-отношение. На рис. 9 приведена иллюстрация реляционной таблицы-отношения R . Формальное определение отношения R (реляционной таблицы) опирается на представление о ее доменах D i , (столбцах) и кортежах K j (строках). Отношением R, определенным на множествах доменов {D i }, называется подмножество декартова (прямого) произведения доменов D 1 *D 2 *…..*D n
Таблица-отношение (см. рис. 1) содержит столбцы с именами элементов данных – атрибутов (А 1 , А 2 , ...). Значения атрибутов d находятся в содержательной части таблицы и образуют строки и столбцы. Множество значений атрибутов в одном столбце образует одиндомен D i . Множество значений атрибутов в одной строке образуют одинкортеж К j . Отношение R образуется множеством упорядоченных кортежей.
R={Кj}, J=1- m Кj={d 1j, d 2 j ,…d nj },
где n – число доменов отношения; определяет размерность отношения;
j – номер кортежа;
m – общее число кортежей в отношении, называемое коорвинальным числом отношения.
Рис.9. Иллюстрация реляционной таблицы-отношения
Домен. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат "истина", то элемент данных является элементом домена.
Наиболее правильной интуитивной трактовкой понятия домена является понимание домена как допустимого потенциального множества значений данного типа. Например, домен "Имена" в нашем примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака).
Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В нашем примере значения доменов "Номера пропусков" и "Номера групп" относятся к типу целых чисел, но не являются сравнимыми. Заметим, что в большинстве реляционных СУБД понятие домена не используется, хотя в Огас1е V.7 оно уже поддерживается.
Схема отношения, схема базы данных. Схема отношения – это именованное множество пар {имя атрибута, имя домена (или типа, если понятие домена не поддерживается)}. Степень или "арность" схемы отношения - мощность этого множества. Степень отношения ПРИМЕРА равна ШЕСТИ, то есть оно является 6-арным. Если все атрибуты одного отношения определены на разных доменах, осмысленно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута). Схема БД (в структурном смысле) – это набор именованных схем отношений.
Список, в котором даются имена реляционных таблиц с перечислением их атрибутов (ключи подчеркнуты) и определений внешних ключей, называется реляционной схемой базы данных. Она является предварительным итогом создания этапа жизненного цикла реляционной базы данных. Пример:
WORKER [WORKER-ID , NAME, HOURLY-RATE, SKILL-TYPE, SVPV-ID]
Внешние ключи: SKILL-TYPE ссылается SKILL
SVPV-ID ссылается WORKER
ASSIGNMENT [WORKER-ID , BLDG-ID , START-DATE, NUMBER-OF-DAYS]
Внешние ключи: WORKER-ID ссылается WORKER
BLDG-ID ссылается BVILDING
BVILDING [BLDG-ID , ADRESS, TYPE, QLTY-LEVEL, STATVS]
SKILL [SKILL- TYPE , BONUS-RATE, HOURS-PER-WEEK]
Кортеж, отношение. Кортеж, соответствующий данной схеме отношения, – это множество пар {имя атрибута, значение, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. "Значение" является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым, степень или "арность" кортежа, т.е. число элементов в нем, совпадает с "арностью" соответствующей схемы отношения. Попросту говоря, кортеж – это набор именованных значений заданного типа.
Отношение – это множество кортежей, соответствующих одной схеме отношения. Иногда, чтобы не путаться, говорят "отношение-схема" и "отношение-экземпляр", иногда схему отношения называют заголовком отношения, а отношение как набор кортежей – телом отношения. На самом деле, понятие схемы отношения ближе всего к понятию структурного типа данных в языках программирования. Было бы вполне логично разрешать отдельно определять схему отношения, а затем одно или несколько отношений с данной схемой.
Однако в реляционных базах данных это не принято. Имя схемы отношения в таких базах данных всегда совпадает с именем соответствующего отношения-экземпляра. В классических реляционных базах данных после определения схемы базы данных изменяются только отношения-экземпляры. В них могут появляться новые и удаляться или модифицироваться существующие кортежи. Однако во многих реализациях допускается и изменение схемы базы данных: определение новых и изменение существующих схем отношения. Это принято называть эволюцией схемы базы данных.
Обычным житейским представлением отношения является таблица, заголовком которой является схема отношения, а строками – кортежи отношения-экземпляра; в этом случае имена атрибутов именуют столбцы этой таблицы. Поэтому иногда говорят "столбец таблицы", имея в виду "атрибут отношения". Когда мы перейдем к рассмотрению практических вопросов организации реляционных баз данных и средств управления, мы будем использовать эту житейскую терминологию. Этой терминологии придерживаются в большинстве коммерческих реляционных СУБД.
Реляционная база данных – это набор отношений, имена которых совпадают с именами схем отношений в схеме БД.
Как видно, основные структурные понятия реляционной модели данных (если не считать понятия домена) имеют очень простую интуитивную интерпретацию, хотя в теории реляционных БД все они определяются абсолютно формально и точно.
Ключ таблицы-отношения. Кортежи не должны повторяться внутри таблицы-отношения и, соответственно они должны иметь уникальный идентификатор – первичный ключ. Один или несколько атрибутов, значения которых однозначно идентифицируют строку таблицы, являютсяключом таблицы.
Первичный ключ называетсяпростым, когда он состоит из одного атрибута, или составным, когда он состоит из нескольких атрибутов. Кроме первичного ключа, в отношении могут существовать и вторичные ключи.
Вторичный ключ – это такой ключ, значения которого могут повторяться в разных строках-кортежах. По ним может отыскиваться группа строк с одинаковым значением вторичного ключа.
Внешний ключ – это набор атрибутов одной таблицы, являющийся ключом другой (или той же самой) таблицы. Внешние ключи обеспечивают важные связи между таблицами. Они используются Для того чтобы связать данные из одной таблицы с данными в другой таблице. Атрибуты внешнего ключа не обязательно должны иметь те же имена, что и атрибуты ключа, которым они соответствуют.
Похожая информация.
Общая характеристика реляционной модели данных
Основы реляционной модели данных были впервые изложены в статье Е.Кодда в 1970 г. Эта работа послужила стимулом для большого количества статей и книг, в которых реляционная модель получила дальнейшее развитие. Наиболее распространенная трактовка реляционной модели данных принадлежит К.Дейту . Согласно Дейту, реляционная модель состоит из трех частей:
Структурной части.
Целостной части.
Манипуляционной части.
Целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность внешних ключей .
Манипуляционная часть описывает два эквивалентных способа манипулирования реляционными данными - реляционную алгебру и реляционное исчисление .
В данной главе рассматривается структурная часть реляционной модели.
^ Типы данных
Любые данные, используемые в программировании, имеют свои типы данных.
Важно! Реляционная модель требует, чтобы типы используемых данных были простыми .
Для уточнения этого утверждения рассмотрим, какие вообще типы данных обычно рассматриваются в программировании. Как правило, типы данных делятся на три группы:
Простые типы данных.
Структурированные типы данных.
Ссылочные типы данных.
Простые, или атомарные, типы данных не обладают внутренней структурой. Данные такого типа называют скалярами . К простым типам данных относятся следующие типы:
Логический.
Строковый.
Численный.
Целый.
Вещественный.
Дата.
Время.
Денежный.
Перечислимый.
Интервальный.
И т.д.…
^
Структурированные типы данных предназначены для задания сложных структур данных. Структурированные типы данных конструируются из составляющих элементов, называемых компонентами, которые, в свою очередь, могут обладать структурой. В качестве структурированных типов данных можно привести следующие типы данных:
Массивы
Записи (Структуры)
Называемое множеством индексов. Отображение
Из множества во множество вещественных чисел задает одномерный вещественный массив. Значение этой функции для некоторого значения индекса называется элементом массива, соответствующим . Аналогично можно задавать многомерные массивы.
Запись (или структура) представляет собой кортеж из некоторого декартового произведения множеств. Действительно, запись представляет собой именованный упорядоченный набор элементов , каждый из которых принадлежит типу . Таким образом, запись ![]() есть элемент множества
есть элемент множества ![]() . Объявляя новые типы записей на основе уже имеющихся типов, пользователь может конструировать сколь угодно сложные типы данных.
. Объявляя новые типы записей на основе уже имеющихся типов, пользователь может конструировать сколь угодно сложные типы данных.
Общим для структурированных типов данных является то, что они имеют внутреннюю структуру , используемую на том же уровне абстракции , что и сами типы данных.
Поясним это следующим образом. При работе с массивами или записями можно манипулировать массивом или записью и как с единым целым (создавать, удалять, копировать целые массивы или записи), так и поэлементно. Для структурированных типов данных есть специальные функции - конструкторы типов, позволяющие создавать массивы или записи из элементов более простых типов.
Работая же с простыми типами данных, например с числовыми, мы манипулируем ими как неделимыми целыми объектами. Чтобы "увидеть", что числовой тип данных на самом деле сложен (является набором битов), нужно перейти на более низкий уровень абстракции. На уровне программного кода это будет выглядеть как ассемблерные вставки в код на языке высокого уровня или использование специальных побитных операций.
^ Ссылочные типы данных
Ссылочный тип данных (указатели ) предназначен для обеспечения возможности указания на другие данные. Указатели характерны для языков процедурного типа, в которых есть понятие области памяти для хранения данных. Ссылочный тип данных предназначен для обработки сложных изменяющихся структур, например деревьев, графов, рекурсивных структур.
^ Типы данных, используемые в реляционной модели
Собственно, для реляционной модели данных тип используемых данных не важен. Требование, чтобы тип данных был простым , нужно понимать так, что в реляционных операциях не должна учитываться внутренняя структура данных . Конечно, должны быть описаны действия, которые можно производить с данными как с единым целым, например, данные числового типа можно складывать, для строк возможна операция конкатенации и т.д.
С этой точки зрения, если рассматривать массив, например, как единое целое и не использовать поэлементных операций, то массив можно считать простым типом данных. Более того, можно создать свой, сколь угодно сложных тип данных, описать возможные действия с этим типом данных, и, если в операциях не требуется знание внутренней структуры данных, то такой тип данных также будет простым с точки зрения реляционной теории. Например, можно создать новый тип - комплексные числа как запись вида , где . Можно описать функции сложения, умножения, вычитания и деления, и все действия с компонентами и выполнять только внутри этих операций. Тогда, если в действиях с этим типом использовать только описанные операции, то внутренняя структура не играет роли, и тип данных извне выглядит как атомарный.
Именно так в некоторых пост-реляционных СУБД реализована работа со сколь угодно сложными типами данных, создаваемых пользователями.
Домены
В реляционной модели данных с понятием тип данных тесно связано понятие домена, которое можно считать уточнением типа данных.
Домен - это семантическое понятие. Домен можно рассматривать как подмножество значений некоторого типа данных имеющих определенный смысл. Домен характеризуется следующими свойствами:
Домен имеет уникальное имя (в пределах базы данных).
Домен определен на некотором простом типе данных или на другом домене.
Домен может иметь некоторое логическое условие , позволяющее описать подмножество данных, допустимых для данного домена.
Домен несет определенную смысловую нагрузку .
Отличие домена от понятия подмножества состоит именно в том, что домен отражает семантику , определенную предметной областью. Может быть несколько доменов, совпадающих как подмножества, но несущие различный смысл. Например, домены "Вес детали" и "Имеющееся количество" можно одинаково описать как множество неотрицательных целых чисел, но смысл этих доменов будет различным, и это будут различные домены.
Основное значение доменов состоит в том, что домены ограничивают сравнения . Некорректно, с логической точки зрения, сравнивать значения из различных доменов, даже если они имеют одинаковый тип. В этом проявляется смысловое ограничение доменов. Синтаксически правильный запрос "выдать список всех деталей, у которых вес детали больше имеющегося количества" не соответствует смыслу понятий "количество" и "вес".
Замечание . Понятие домена помогает правильно моделировать предметную область. При работе с реальной системой в принципе возможна ситуация когда требуется ответить на запрос, приведенный выше. Система даст ответ, но, вероятно, он будет бессмысленным.
Замечание . Не все домены обладают логическим условием, ограничивающим возможные значения домена. В таком случае множество возможных значений домена совпадает с множеством возможных значений типа данных.
Замечание . Не всегда очевидно, как задать логическое условие, ограничивающее возможные значения домена. Я буду благодарен тому, кто приведет мне условие на строковый тип данных, задающий домен "Фамилия сотрудника". Ясно, что строки, являющиеся фамилиями не должны начинаться с цифр, служебных символов, с мягкого знака и т.д. Но вот является ли допустимой фамилия "Ггггггыыыыы"? Почему бы нет? Очевидно, нет! А может кто-то назло так себя назовет. Трудности такого рода возникают потому, что смысл реальных явлений далеко не всегда можно формально описать. Просто мы, как все люди, интуитивно понимаем, что такое фамилия, но никто не может дать такое формальное определение, которое отличало бы фамилии от строк, фамилиями не являющимися. Выход из этой ситуации простой - положиться на разум сотрудника, вводящего фамилии в компьютер.
^ Отношения, атрибуты, кортежи отношения
Определения и примеры
Фундаментальным понятием реляционной модели данных является понятие отношения . В определении понятия отношения будем следовать книге К. Дейта .
Определение 1. Атрибут отношения есть пара вида <Имя_атрибута: Имя_домена>.
Имена атрибутов должны быть уникальны в пределах отношения. Часто имена атрибутов отношения совпадают с именами соответствующих доменов.
Определение 2 . Отношение , определенное на множестве доменов (не обязательно различных), содержит две части: заголовок и тело.
Заголовок отношения содержит фиксированное количество атрибутов отношения:
Тело отношения содержит множество кортежей отношения. Каждый кортеж отношения представляет собой множество пар вида <Имя_атрибута: Значение_атрибута>:
Таких что значение атрибута принадлежит домену
Отношение обычно записывается в виде:
Или короче
![]() ,
,
Или просто
Число атрибутов в отношении называют степенью (или -арностью ) отношения.
Мощность множества кортежей отношения называют мощностью отношения.
Возвращаясь к математическому понятию отношения, введенному в предыдущей главе, можно сделать следующие выводы:
Вывод 1 . Заголовок отношения описывает декартово произведение доменов, на котором задано отношение. Заголовок статичен, он не меняется во время работы с базой данных. Если в отношении изменены, добавлены или удалены атрибуты, то в результате получим уже другое отношение (пусть даже с прежним именем).
Вывод 2 . Тело отношения представляет собой набор кортежей, т.е. подмножество декартового произведения доменов. Таким образом, тело отношения собственно и является отношением в математическом смысле слова. Тело отношения может изменяться во время работы с базой данных - кортежи могут изменяться, добавляться и удаляться.
Пример 1 . Рассмотрим отношение "Сотрудники" заданное на доменах "Номер_сотрудника", "Фамилия", "Зарплата", "Номер_отдела". Т.к. все домены различны, то имена атрибутов отношения удобно назвать так же, как и соответствующие домены. Заголовок отношения имеет вид:
Сотрудники (Номер_сотрудника, Фамилия, Зарплата, Номер_отдела)
Пусть в данный момент отношение содержит три кортежа:
(1,Иванов, 1000, 1)
(2, Петров, 2000, 2)
(3, Сидоров, 3000, 1)
Такое отношение естественным образом представляется в виде таблицы:
^
Таблица 1 Отношение "Сотрудники"
Определение 3 . Реляционной базой данных называется набор отношений.
Определение 4 . Схемой реляционной базы
Хотя любое отношение можно изобразить в виде таблицы, нужно четко понимать, что отношения не являются таблицами . Это близкие, но не совпадающие понятия. Различия между отношениями и таблицами будут рассмотрены ниже.
Термины, которыми оперирует реляционная модель данных , имеют соответствующие "табличные" синонимы:
| ^ Реляционный термин | Соответствующий "табличный" термин |
| База данных | Набор таблиц |
| Схема базы данных | Набор заголовков таблиц |
| Отношение | Таблица |
| Заголовок отношения | Заголовок таблицы |
| Тело отношения | Тело таблицы |
| Атрибут отношения | Наименование столбца таблицы |
| Кортеж отношения | Строка таблицы |
| Степень (-арность) отношения | Количество столбцов таблицы |
| Мощность отношения | Количество строк таблицы |
| Домены и типы данных | Типы данные в ячейках таблицы |
^ Свойства отношений
Свойства отношений непосредственно следуют из приведенного выше определения отношения. В этих свойствах в основном и состоят различия между отношениями и таблицами.
^ В отношении нет одинаковых кортежей . Действительно, тело отношения есть множество кортежей и, как всякое множество, не может содержать неразличимые элементы (см. понятие множества в гл.1.). Таблицы в отличие от отношений могут содержать одинаковые строки.
^ Кортежи не упорядочены (сверху вниз) . Действительно, несмотря на то, что мы изобразили отношение "Сотрудники" в виде таблицы, нельзя сказать, что сотрудник Иванов "предшествует" сотруднику Петрову. Причина та же - тело отношения есть множество, а множество не упорядочено. Это вторая причина, по которой нельзя отождествить отношения и таблицы - строки в таблицах упорядочены. Одно и то же отношение может быть изображено разными таблицами, в которых строки идут в различном порядке .
^ Атрибуты не упорядочены (слева направо) . Т.к. каждый атрибут имеет уникальное имя в пределах отношения, то порядок атрибутов не имеет значения. Это свойство несколько отличает отношение от математического определения отношения (см. гл.1 - компоненты кортежей там упорядочены ). Это также третья причина, по которой нельзя отождествить отношения и таблицы - столбцы в таблице упорядочены. Одно и то же отношение может быть изображено разными таблицами, в которых столбцы идут в различном порядке .
^ Все значения атрибутов атомарны . Это следует из того, что лежащие в их основе атрибуты имеют атомарные значения. Это четвертое отличие отношений от таблиц - в ячейки таблиц можно поместить что угодно - массивы, структуры, и даже другие таблицы.
Замечание . Каждое отношение можно считать классом эквивалентности таблиц , для которых выполняются следующие условия:
Таблицы имеют одинаковое количество столбцов.
Таблицы содержат столбцы с одинаковыми наименованиями.
Столбцы с одинаковыми наименованиями содержат данные из одних и тех же доменов.
Таблицы имеют одинаковые строки с учетом того, что порядок столбцов может различаться.
^ Первая нормальная форма
Труднее всего дать определение вещей, которые всем понятны. Если давать не строгое, описательное определение, то всегда остается возможность неправильной его трактовки. Если дать строгое формальное определение, то оно, как правило, или тривиально, или слишком громоздко. Именно такая ситуация с определением отношения в Первой Нормальной Форме (1НФ ). Совсем не говорить об этом нельзя, т.к. на основе 1НФ строятся более высокие нормальные формы, которые рассматриваются далее в гл. 6 и 7. Дать определение 1НФ сложно ввиду его тривиальности. Поэтому, дадим просто несколько объяснений.
Объяснение 1 . Говорят, что отношение находится в 1НФ, если оно удовлетворяет определению 2.
Это, собственно, тавтология, ведь из определения 2 следует, что других отношений не бывает. Действительно, определение 2 описывает, что является отношением, а что - нет, следовательно, отношений в непервой нормальной форме просто нет.
Объяснение 2 . Говорят, что отношение находится в 1НФ, если его атрибуты содержат только скалярные (атомарные) значения.
Опять же, определение 2 опирается на понятие домена, а домены определены на простых типах данных.
Непервую нормальную форму можно получить, если допустить, что атрибуты отношения могут быть определены на сложных типах данных - массивах, структурах, или даже на других отношениях. Легко себе представить таблицу, у которой в некоторых ячейках содержатся массивы, в других ячейках - определенные пользователями сложные структуры, а в третьих ячейках - целые реляционные таблицы, которые в свою очередь могут содержать такие же сложные объекты. Именно такие возможности предоставляются некоторыми современными пост-реляционными и объектными СУБД.
Требование, что отношения должны содержать только данные простых типов, объясняет, почему отношения иногда называют плоскими таблицами (plain table ). Действительно, таблицы, задающие отношения двумерны. Одно измерение задается списком столбцов, второе измерение задается списком строк. Пара координат (Номер строки, Номер столбца) однозначно идентифицирует ячейку таблицы и содержащееся в ней значение. Если же допустить, что в ячейке таблицы могут содержаться данные сложных типов (массивы, структуры, другие таблицы), то такая таблица будет уже не плоской. Например, если в ячейке таблицы содержится массив, то для обращения к элементу массива нужно знать три параметра (Номер строки, Номер столбца, номер элемента в массиве).
Таким образом появляется третье объяснение Первой Нормальной Формы:
Объяснение 3 . Отношение находится в 1НФ, если оно является плоской таблицей.
Мы сознательно ограничиваемся рассмотрением только классической реляционной теории, в которой все отношения имеют только атомарные атрибуты и заведомо находятся в 1НФ.
Выводы
Реляционная модель данных состоит из трех частей:
Структурной части.
Целостной части.
Манипуляционной части.
Домены - это типы данных, имеющие некоторый смысл (семантику). Домены ограничивают сравнения - некорректно, хотя и возможно, сравнивать значения из различных доменов.
Отношение состоит из двух частей - заголовка отношения и тела отношения . Заголовок отношения - это аналог заголовка таблицы. Заголовок отношения состоит из атрибутов. Количество атрибутов называется степенью отношения . Тело отношения - это аналог тела таблицы. Тело отношения состоит из кортежей . Кортеж отношения является аналогом строки таблицы. Количество кортежей отношения называется мощностью отношения .
Отношение обладает следующими свойствами:
В отношении нет одинаковых кортежей.
Кортежи не упорядочены (сверху вниз).
Атрибуты не упорядочены (слева направо).
Все значения атрибутов атомарны.
Схемой реляционной базы данных называется набор заголовков отношений, входящих в базу данных.
Отношение находится в Первой Нормальной Форме (1НФ ), если оно содержит только скалярные (атомарные) значения.
Которая является приложением к задачам обработки данных таких разделов математики как теории множеств и логика первого порядка .
На реляционной модели данных строятся реляционные базы данных .
Реляционная модель данных включает следующие компоненты:
- Структурный аспект (составляющая) - данные в базе данных представляют собой набор отношений .
- Аспект (составляющая) целостности - отношения (таблицы) отвечают определенным условиям целостности . РМД поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения и уровня базы данных.
- Аспект (составляющая) обработки (манипулирования) - РМД поддерживает операторы манипулирования отношениями (реляционная алгебра , реляционное исчисление).
Основными понятиями реляционных баз данных являются тип данных, отношение, сущность, атрибут, домен, кортеж, первичный ключ.
Понятие тип данных в реляционной модели данных полностью аналогично понятию типа данных в языках программирования. Обычно в современных реляционных базах данных допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как деньги), а также специальных данных (дата, время, временной интервал).
Отношение является важнейшим понятием и представляет собой двумерную таблицу, содержащую некоторые данные.
Сущность – некоторый обособленный объект или событие, информацию о котором необходимо сохранять в базе данных и который имеет определенный набор свойств – атрибутов. Сущностями могут быть как физические (реально существующие) объекты, например СТУДЕНТ (атрибуты – Номер зачетной книжки, Фамилия, Имя, Отчество, Специальность, Номер группы и т.д.), так и абстрактные, например ЭКЗАМЕН (атрибуты – Дисциплина, Дата, Преподаватель, Аудитория и пр.). Для сущностей различают тип и экземпляр. Тип характеризуется именем и списком свойств, а экземпляр – конкретными значениями свойств.
Атрибуты представляют собой свойства, характеризующие сущность. В структуре таблицы каждый атрибут именуется и ему соответствует заголовок некоторого столбца таблицы. Атрибуты сущности бывают:
1) идентифицирующие и описательные. Идентифицирующие атрибуты имеют уникальное значение для сущностей данного типа и являются потенциальными ключами. Они позволяют однозначно распознавать экземпляры сущности. Из потенциальных ключей выбирается один первичный ключ. В качестве первичного ключа обычно выбирается потенциальный ключ, по которому чаще происходит обращение к экземплярам записи. Первичный ключ должен включать в свой состав минимально необходимое для идентификации количество атрибутов. Остальные атрибуты называются описательными;
2) простые и составные. Простой атрибут состоит из одного компонента, его значение неделимо. Составной атрибут является комбинацией нескольких компонентов, возможно принадлежащих разным типам данных (например, адрес). Решение о том, использовать составной атрибут или разбивать его на компоненты, зависит от особенностей процессов его применения и может быть связано с обеспечением высокой скорости работы с большими базами данных;
3) однозначные и многозначные. Атрибуты могут иметь соответственно одно или много значений для каждого экземпляра сущности;
4) основные и производные. Значение основного атрибута не зависит от других атрибутов. Значение производного атрибута вычисляется на основе значений других атрибутов (например, возраст человека вычисляется на основе даты его рождения и текущей даты).
Спецификация атрибута состоит из его названия, указания типа данных и описания ограничений целостности – множества значений (или домена), которые может принимать данный атрибут.
Домен представляет собой множество всех возможных значений определенного атрибута отношения.
Схема отношения (заголовок отношения) представляет собой список имен атрибутов с указанием имен доменов.
Кортеж, соответствующий данной схеме отношения, представляет собой множество пар (имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута. Аргумент “значение” является допустимым значением домена данного атрибута.
Первичным ключом (ключом отношения, ключевым атрибутом) называется атрибут или набор атрибутов отношения, однозначно идентифицирующий каждый из его кортежей. Первичный ключ по определению уникален: в отношении не может быть двух разных кортежей с одинаковыми значениями первичного ключа. Атрибуты, составляющие первичный ключ, не могут иметь значение NULL. Понятие NULL в теории реляционных баз данных призвано обозначать отсутствие какого-либо значения атрибута. Для каждого отношения первичный ключ может быть только один.
Каждое отношение обязательно имеет комбинацию атрибутов, которая может служить ключом. Возможны случаи, когда отношение имеет несколько комбинаций атрибутов, каждая из которых однозначно определяет все кортежи отношения. Все эти комбинации атрибутов являются возможными ключами отношения. Любой из возможных ключей может быть выбран как первичный.
Внешние ключи – это основной механизм для организации связей между таблицами и поддержания целостности и непротиворечивости информации в базе данных.
Внешний ключ – это набор атрибутов одного отношения, являющийся возможным ключом другого отношения.
Благодаря наличию связок между возможными и внешними ключами обеспечивается взаимосвязь кортежей определенных отношений, которая тем самым способствует поддержке базы данных в таком состоянии, что ее можно рассматривать как единое целое. Отношение, содержащее внешний ключ, называется дочерним, а отношение, содержащее связанный с внешним ключом возможный ключ, – родительским. Типы данных (а в некоторых СУБД и размерности) соответствующих атрибутов внешнего и родительского ключей должны совпадать.
Элементы реляционной модели данных и форма их представления
|
Элемент реляционной модели |
Форма представления |
|
|
Отношение |
||
|
Схема отношения |
Строка заголовков столбцов таблицы (заголовок таблицы) |
|
|
Строка таблицы |
||
|
Сущность |
Описание свойств объекта |
|
|
Заголовок столбца таблицы |
||
|
Множество допустимых значений атрибута |
||
|
Значение атрибута |
Значение поля в записи |
|
|
Первичный ключ |
Один или несколько атрибутов |
|
|
Тип данных |
Тип значений элементов таблицы |
|
Появление компьютерной техники в нашей современности ознаменовало информационный переворот во всех сферах человеческой деятельности. Но для того, чтобы вся информация не стала ненужным мусором в глобальной сети Интернет, была изобретена система баз данных, в которой материалы сортируются, систематизируются, в результате чего их легко отыскать и представить последующей обработке. Существуют три основные разновидности - выделяют базы данных реляционные, иерархические, сетевые.
Фундаментальные модели
Возвращаясь к возникновению баз данных, стоит сказать, что этот процесс был достаточно сложным, он берет свое начало вместе с развитием программируемого оборудования обработки информации. Поэтому неудивительно, что количество их моделей на данный момент достигает более 50, но основными из них считаются иерархическая, реляционная и сетевая, которые и до сих пор широко применяются на практике. Что же они собой представляют?
Иерархическая имеет древовидную структуру и составляется из данных разных уровней, между которыми существуют связи. Сетевая модель БД представляет собой более сложный шаблон. Ее структура напоминает иерархическую, а схема расширенная и усовершенствованная. Разница между ними в том, что потомственные данные иерархической модели могут иметь связь только с одним предком, а у сетевой их может быть несколько. Структура реляционной базы данных гораздо сложнее. Поэтому ее следует разобрать более подробно.
Основное понятие реляционной базы данных
Такая модель была разработана в 1970-х годах доктором науки Эдгаром Коддом. Она представляет собой логически структурированную таблицу с полями, описывающую данные, их отношения между собой, операции, произведенные над ними, а главное - правила, которые гарантируют их целостность. Почему модель называется реляционной? В ее основе лежат отношения (от лат. relatio) между данными. Существует множество определений этого типа базы данных. Реляционные таблицы с информацией гораздо проще систематизировать и придать обработке, нежели в сетевой или иерархической модели. Как же это сделать? Достаточно знать особенности, структуру модели и свойства реляционных таблиц.

Процесс моделирования и составления основных элементов
Для того чтобы создать собственную СУБД, следует воспользоваться одним из инструментов моделирования, продумать, с какой информацией вам необходимо работать, спроектировать таблицы и реляционные одно- и множественные связи между данными, заполнить ячейки сущностей и установить первичный, внешние ключи.
Моделирование таблиц и проектирование реляционных баз данных производится посредством бесплатных инструментов, таких как Workbench, PhpMyAdmin, Case Studio, dbForge Studio. После детальной проектировки следует сохранить графически готовую реляционную модель и перевести ее в готовый SQL-код. На этом этапе можно начинать работу с сортировкой данных, их обработку и систематизацию.

Особенности, структура и термины, связанные с реляционной моделью
Каждый источник по-своему описывает ее элементы, поэтому для меньшей путаницы хотелось бы привести небольшую подсказку:
- реляционная табличка = сущность;
- макет = атрибуты = наименование полей = заголовок столбцов сущности;
- экземпляр сущности = кортеж = запись = строка таблички;
- значение атрибута = ячейка сущности= поле.

Для перехода к свойствам реляционной базы данных следует знать, из каких базовых компонентов она состоит и для чего они предназначены.
- Сущность. Таблица реляционной базы данных может быть одна, а может быть целый набор из таблиц, которые характеризируют описанные объекты благодаря хранящимся в них данным. У них фиксированное количество полей и переменное число записей. Таблица реляционной модели баз данных составляется из строк, атрибутов и макета.
- Запись - переменное число строк, отображающих данные, что характеризируют описываемый объект. Нумерация записей производится системой автоматически.
- Атрибуты - данные, демонстрирующие собой описание столбцов сущности.
- Поле. Представляет собой столбец сущности. Их количество - фиксированная величина, устанавливаемая во время создания или изменения таблицы.

Теперь, зная составляющие элементы таблицы, можно переходить к свойствам реляционной модели database:
- Сущности реляционной БД двумерные. Благодаря этому свойству с ними легко проделывать различные логические и математические операции.
- Порядок следования значений атрибутов и записей в реляционной таблице может быть произвольным.
- Столбец в пределах одной реляционной таблицы должен иметь свое индивидуальное название.
- Все данные в столбце сущности имеют фиксированную длину и одинаковый тип.
- Любая запись в сущности считается одним элементом данных.
- Составляющие компоненты строк единственны в своем роде. В реляционной сущности отсутствуют одинаковые строки.
Исходя из свойств понятно, что значения атрибутов должны быть одинакового типа, длины. Рассмотрим особенности значений атрибутов.
Основные характеристики полей реляционных БД
Названия полей должны быть уникальными в рамках одной сущности. Типы атрибутов или полей реляционных баз данных описывают, данные какой категории хранятся в полях сущностей. Поле реляционной базы данных должно иметь фиксированный размер, исчисляемый в символах. Параметры и формат значений атрибутов определяют манеру исправления в них данных. Еще есть такое понятие, как "маска", или "шаблон ввода". Оно предназначено для определения конфигурации ввода данных в значение атрибута. Непременно при записи неправильного в поле должно выдаваться извещение об ошибке. Также на элементы полей накладываются некоторые ограничения - условия проверки точности и безошибочности ввода данных. Существует некоторое обязательное значение атрибута, которое однозначно должно быть заполнено данными. Некоторые строки атрибутов могут быть заполнены NULL-значениями. Разрешается ввод пустых данных в атрибуты полей. Как и извещение об ошибке, есть значения, которые заполняются системой автоматически - это данные по умолчанию. Для ускорения поиска любых данных предназначено индексированное поле.

Схема двумерной реляционной таблицы базы данных
Для детального понимания модели с помощью SQL лучше всего рассмотреть схему на примере. Нам уже известно, что представляет собой реляционная БД. Запись в каждой таблице - это один элемент данных. Чтобы предотвратить избыточность данных, необходимо провести операции нормализации.
Базовые правила нормализации реляционной сущности
1. Значение названия поля для реляционной таблицы должно быть уникальным, единственным в своем роде (первая нормальная форма - 1НФ).
2. Для таблицы, которая уже приведена к 1НФ, наименование любого неидентифицирующего столбца должно быть зависимым от уникального идентификатора таблицы (2НФ).
3. Для всей таблицы, что уже находится в 2НФ, каждое неидентифицирующее поле не может зависеть от элемента другого неопознанного значения (3НФ сущности).
Базы данных: реляционные связи между таблицами
Существует 2 основных реляционных табличек:
- «Один-многие». Возникает при соответствии одной ключевой записи таблицы №1 нескольким экземплярам второй сущности. Значок ключа на одном из концов проведенной линии говорит о том, что сущность находится на стороне «один», второй конец линии зачастую отмечают символом бесконечности.

- Связь «много-много» образуется в случае возникновения между несколькими строками одной сущности явного логичного взаимодействия с рядом записей другой таблицы.
- Если между двумя сущностями возникает конкатенация «один к одному», это значит, что ключевой идентификатор одной таблицы присутствует в другой сущности, тогда следует убрать одну из таблиц, она лишняя. Но иногда исключительно в целях безопасности программисты преднамеренно разделяют две сущности. Поэтому гипотетически связь «один к одному» может существовать.
Существование ключей в реляционной базе данных
Первичный и вторичный ключи определяют потенциальные отношения базы данных. Реляционные связи модели данных могут иметь только один потенциальный ключ, это и будет primary key. Что же он собой представляет? Первичный ключ - это столбец сущности или набор атрибутов, благодаря которому можно получить доступ к данным конкретной строки. Он должен быть уникальным, единственным, а его поля не могут содержать пустых значений. Если первичный ключ состоит всего из одного атрибута, тогда он называется простым, в ином случае будет составляющим.
Кроме первичного ключа, существует и внешний (foreign key). Многие не понимают, какая между ними разница. Разберем их более детально на примере. Итак, существует 2 таблицы: «Деканат» и «Студенты». Сущность «Деканат» содержит поля: «ID студента», «ФИО» и «Группа». Таблица «Студенты» имеет такие значения атрибутов, как «ФИО», «Группа» и «Средний бал». Так как ID студента не может быть одинаковым для нескольких студентов, это поле и будет первичным ключом. «ФИО» и «Группа» из таблицы «Студенты» могут быть одинаковыми для нескольких человек, они ссылаются на ID номер студента из сущности «Деканат», поэтому могут быть использованы в качестве внешнего ключа.
Пример модели реляционной базы данных
Для наглядности приведем простой пример реляционной модели базы данных, состоящей из двух сущностей. Существует таблица с названием «Деканат».
Необходимо провести связи, чтобы получилась полноценная реляционная база данных. Запись "ИН-41", как и "ИН-72", может присутствовать не единожды в табличке "Деканат", также фамилия, имя и отчество студентов в редких случаях могут совпадать, поэтому данные поля никак нельзя сделать первичным ключом. Покажем сущность «Студенты».
Как мы видим, типы полей реляционных баз данных совершенно различаются. Присутствуют как цифровые записи, так и символьные. Поэтому в настройках атрибутов следует указывать значения integer, char, vachar, date и другие. В таблице "Деканат" уникальным значением является только ID студента. Данное поле можно взять за первичный ключ. ФИО, группа и телефон из сущности "Студенты" могут быть взяты как внешний ключ, ссылающийся на ID студента. Связь установлена. Это пример модели со связью «один к одному». Гипотетически одна из таблиц лишняя, их можно легко объединить в одну сущность. Чтобы ID-номера студентов не стали всеобще известными, вполне реально существование двух таблиц.