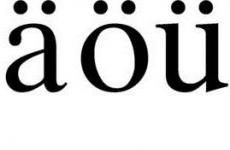Буквы перевести в двоичный код. Запись текстов двоичным кодом (Запись букв двоичным кодом). Единицы компьютерной информации
Одиночный цифровой сигнал не слишком информативен, ведь он может принимать только два значения: нуль и единица. Поэтому в тех случаях, когда необходимо передавать, обрабатывать или хранить большие объемы информации, обычно применяют несколько параллельных цифровых сигналов. При этом все эти сигналы должны рассматриваться только одновременно, каждый из них по отдельности не имеет смысла. В таких случаях говорят о двоичных кодах, то есть о кодах, образованных цифровыми (логическими, двоичными) сигналами. Каждый из логических сигналов, входящих в код, называется разрядом. Чем больше разрядов входит в код, тем больше значений может принимать данный код.
В отличие от привычного для нас десятичного кодирования чисел, то есть кода с основанием десять, при двоичном кодировании в основании кода лежит число два (рис. 2.9). То есть каждая цифра кода (каждый разряд) двоичного кода может принимать не десять значений (как в десятичном коде: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9), а всего лишь два - 0 и 1. Система позиционной записи остается такой же, то есть справа пишется самый младший разряд, а слева - самый старший. Но если в десятичной системе вес каждого следующего разряда больше веса предыдущего в десять раз, то в двоичной системе (при двоичном кодировании) - в два раза. Каждый разряд двоичного кода называется бит (от английского "Binary Digit" - "двоичное число").
Рис. 2.9. Десятичное и двоичное кодирование
В табл. 2.3 показано соответствие первых двадцати чисел в десятичной и двоичной системах.
Из таблицы видно, что требуемое количество разрядов двоичного кода значительно больше, чем требуемое количество разрядов десятичного кода. Максимально возможное число при количестве разрядов, равном трем, составляет при десятичной системе 999, а при двоичной - всего лишь 7 (то есть 111 в двоичном коде). В общем случае n-разрядное двоичное число может принимать 2 n различных значений, а n-разрядное десятичное число - 10 n значений. То есть запись больших двоичных чисел (с количеством разрядов больше десяти) становится не слишком удобной.
| Таблица 2.3. Соответствие чисел в десятичной и двоичной системах | |||
| Десятичная система | Двоичная система | Десятичная система | Двоичная система |
Для того чтобы упростить запись двоичных чисел, была предложена так называемая шестнадцатеричная система (16-ричное кодирование). В этом случае все двоичные разряды разбиваются на группы по четыре разряда (начиная с младшего), а затем уже каждая группа кодируется одним символом. Каждая такая группа называется полубайтом (или нибблом , тетрадой ), а две группы (8 разрядов) - байтом. Из табл. 2.3 видно, что 4-разрядное двоичное число может принимать 16 разных значений (от 0 до 15). Поэтому требуемое число символов для шестнадцатиричного кода тоже равно 16, откуда и происходит название кода. В качестве первых 10 символов берутся цифры от 0 до 9, а затем используются 6 начальных заглавных букв латинского алфавита: A, B, C, D, E, F.

Рис. 2.10. Двоичная и 16-ричная запись числа
В табл. 2.4 приведены примеры 16-ричного кодирования первых 20 чисел (в скобках приведены двоичные числа), а на рис. 2.10 показан пример записи двоичного числа в 16-ричном виде. Для обозначения 16-ричного кодирования иногда применяют букву "h" или "H" (от английского Hexadecimal) в конце числа, например, запись A17F h обозначает 16-ричное число A17F. Здесь А1 представляет собой старший байт числа, а 7F - младший байт числа. Все число (в нашем случае - двухбайтовое) называется словом .
| Таблица 2.4. 16-ричная система кодирования | |||
| Десятичная система | 16-ричная система | Десятичная система | 16-ричная система |
| 0 (0) | A (1010) | ||
| 1(1) | B (1011) | ||
| 2 (10) | C (1100) | ||
| 3 (11) | D (1101) | ||
| 4 (100) | E (1110) | ||
| 5 (101) | F (1111) | ||
| 6 (110) | 10 (10000) | ||
| 7 (111) | 11 (10001) | ||
| 8 (1000) | 12 (10010) | ||
| 9 (1001) | 13 (10011) |
Для перевода 16-ричного числа в десятичное необходимо умножить значение младшего (нулевого) разряда на единицу, значение следующего (первого) разряда на 16, второго разряда на 256 (16 2) и т.д., а затем сложить все произведения. Например, возьмем число A17F:
A17F=F*16 0 + 7*16 1 + 1*16 2 + A*16 3 = 15*1 + 7*16+1*256+10*4096=41343
Но каждому специалисту по цифровой аппаратуре (разработчику, оператору, ремонтнику, программисту и т.д.) необходимо научиться так же свободно обращаться с 16-ричной и двоичной системами, как и с обычной десятичной, чтобы никаких переводов из системы в систему не требовалось.
Помимо рассмотренных кодов, существует также и так называемое двоично-десятичное представление чисел. Как и в 16-ричном коде, в двоично-десятичном коде каждому разряду кода соответствует четыре двоичных разряда, однако каждая группа из четырех двоичных разрядов может принимать не шестнадцать, а только десять значений, кодируемых символами 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. То есть одному десятичному разряду соответствует четыре двоичных. В результате получается, что написание чисел в двоично-десятичном коде ничем не отличается от написания в обычном десятичном коде (табл. 2.6), но в реальности это всего лишь специальный двоичный код, каждый разряд которого может принимать только два значения: 0 и 1. Двоично-десятичный код иногда очень удобен для организации десятичных цифровых индикаторов и табло.
| Таблица 2.6. Двоично-десятичная система кодирования | |||
| Десятичная система | Двоично-десятичная система | Десятичная система | Двоично-десятичная система |
| 0 (0) | 10 (1000) | ||
| 1(1) | 11 (1001) | ||
| 2 (10) | 12 (10010) | ||
| 3 (11) | 13 (10011) | ||
| 4 (100) | 14 (10100) | ||
| 5 (101) | 15 (10101) | ||
| 6 (110) | 16 (10110) | ||
| 7 (111) | 17 (10111) | ||
| 8 (1000) | 18 (11000) | ||
| 9 (1001) | 19 (11001) |
В двоичном коде над числами можно проделывать любые арифметические операции: сложение, вычитание, умножение, деление.
Рассмотрим, например, сложение двух 4-разрядных двоичных чисел. Пусть надо сложить число 0111 (десятичное 7) и 1011 (десятичное 11). Сложение этих чисел не сложнее, чем в десятичном представлении:
При сложении 0 и 0 получаем 0, при сложении 1 и 0 получаем 1, при сложении 1 и 1 получаем 0 и перенос в следующий разряд 1. Результат - 10010 (десятичное 18). При сложении любых двух n-разрядных двоичных чисел может получиться n-разрядное или (n+1)-разрядное число.
Точно так же производится вычитание. Пусть из числа 10010 (18) надо вычесть число 0111 (7). Записываем числа с выравниванием по младшему разряду и вычитаем точно так же, как в случае десятичной системы:
При вычитании 0 из 0 получаем 0, при вычитании 0 из 1 получаем 1, при вычитании 1 из 1 получаем 0, при вычитании 1 из 0 получаем 1 и заем 1 в следующем разряде. Результат - 1011 (десятичное 11).
При вычитании возможно получение отрицательных чисел, поэтому необходимо использовать двоичное представление отрицательных чисел.
Для одновременного представления как двоичных положительных, так и двоичных отрицательных чисел чаще всего используется так называемый дополнительный код. Отрицательные числа в этом коде выражаются таким числом, которое, будучи сложено с положительным числом такой же величины, даст в результате нуль. Для того чтобы получить отрицательное число, надо поменять все биты такого же положительного числа на противоположные (0 на 1, 1 на 0) и прибавить к результату 1. Например, запишем число –5. Число 5 в двоичном коде выглядит 0101. Заменяем биты на противоположные: 1010 и прибавляем единицу: 1011. Суммируем результат с исходным числом: 1011 + 0101 = 0000 (перенос в пятый разряд игнорируем).
Отрицательные числа в дополнительном коде отличаются от положительных значением старшего разряда: единица в старшем разряде определяет отрицательное число, а нуль - положительное.
Помимо стандартных арифметических операций, в двоичной системе счисления используются и некоторые специфические операции, например, сложение по модулю 2. Эта операция (обозначается A) является побитовой, то есть никаких переносов из разряда в разряд и заемов в старших разрядах здесь не существует. Правила сложения по модулю 2 следующие: , , . Эта же операция называется функцией Исключающее ИЛИ . Например, просуммируем по модулю 2 два двоичных числа 0111 и 1011:
Среди других побитовых операций над двоичными числами можно отметить функцию И и функцию ИЛИ. Функция И дает в результате единицу только тогда, когда в соответствующих битах двух исходных чисел обе единицы, в противном случае результат -0. Функция ИЛИ дает в результате единицу тогда, когда хотя бы один из соответствующих битов исходных чисел равен 1, в противном случае результат 0.
08. 06.2018
Блог Дмитрия Вассиярова.
Двоичный код — где и как применяется?
Сегодня я по-особому рад своей встрече с вами, дорогие мои читатели, ведь я чувствую себя учителем, который на самом первом уроке начинает знакомить класс с буквами и цифрами. А поскольку мы живем в мире цифровых технологий, то я расскажу вам, что такое двоичный код, являющийся их основой.

Начнем с терминологии и выясним, что означит двоичный. Для пояснения вернемся к привычному нам исчислению, которое называется «десятичным». То есть, мы используем 10 знаков-цифр, которые дают возможность удобно оперировать различными числами и вести соответствующую запись.
Следуя этой логике, двоичная система предусматривает использование только двух знаков. В нашем случае, это всего лишь «0» (ноль) и «1» единица. И здесь я хочу вас предупредить, что гипотетически на их месте могли бы быть и другие условные обозначения, но именно такие значения, обозначающие отсутствие (0, пусто) и наличие сигнала (1 или «палочка»), помогут нам в дальнейшем уяснить структуру двоичного кода.
Зачем нужен двоичный код?
До появления ЭВМ использовались различные автоматические системы, принцип работы которых основан на получении сигнала. Срабатывает датчик, цепь замыкается и включается определенное устройство. Нет тока в сигнальной цепи – нет и срабатывания. Именно электронные устройства позволили добиться прогресса в обработке информации, представленной наличием или отсутствием напряжения в цепи.

Дальнейшее их усложнение привело к появлению первых процессоров, которые так же выполняли свою работу, обрабатывая уже сигнал, состоящий из импульсов, чередующихся определенным образом. Мы сейчас не будем вникать в программные подробности, но для нас важно следующее: электронные устройства оказались способными различать заданную последовательность поступающих сигналов. Конечно, можно и так описать условную комбинацию: «есть сигнал»; «нет сигнала»; «есть сигнал»; «есть сигнал». Даже можно упростить запись: «есть»; «нет»; «есть»; «есть».
Но намного проще обозначить наличие сигнала единицей «1», а его отсутствие – нулем «0». Тогда мы вместо всего этого сможем использовать простой и лаконичный двоичный код: 1011.
Безусловно, процессорная техника шагнула далеко вперед и сейчас чипы способны воспринимать не просто последовательность сигналов, а целые программы, записанные определенными командами, состоящими из отдельных символов.
Но для их записи используется все тот же двоичный код, состоящий из нулей и единиц, соответствующий наличию или отсутствию сигнала. Есть он, или его нет – без разницы. Для чипа любой из этих вариантов – это единичная частичка информации, которая получила название «бит» (bit — официальная единица измерения).
Условно, символ можно закодировать последовательностью из нескольких знаков. Двумя сигналами (или их отсутствием) можно описать всего четыре варианта: 00; 01;10; 11. Такой способ кодирования называется двухбитным. Но он может быть и:
- Четырехбитным (как в примере на абзац выше 1011) позволяет записать 2^4 = 16 комбинаций-символов;
- Восьмибитным (например: 0101 0011; 0111 0001). Одно время он представлял наибольший интерес для программирования, поскольку охватывал 2^8 = 256 значений. Это давало возможность описать все десятичные цифры, латинский алфавит и специальные знаки;
- Шестнадцатибитным (1100 1001 0110 1010) и выше. Но записи с такой длинной – это уже для современных более сложных задач. Современные процессоры используют 32-х и 64-х битную архитектуру;
Скажу честно, единой официальной версии нет, то так сложилось, что именно комбинация из восьми знаков стала стандартной мерой хранящейся информации, именуемой «байт». Таковая могла применяться даже к одной букве, записанной 8-и битным двоичным кодом. Итак, дорогие мои друзья, запомните пожалуйста (если кто не знал):
8 бит = 1 байт.

Так принято. Хотя символ, записанный 2-х или 32-х битным значением так же номинально можно назвать байтом. Кстати, благодаря двоичному коду мы можем оценивать объемы файлов, измеряемые в байтах и скорость передачи информации и интернета (бит в секунду).
Бинарная кодировка в действии
Для стандартизации записи информации для компьютеров было разработано несколько кодировочных систем, одна из которых ASCII, базирующаяся на 8-и битной записи, получила широкое распространение. Значения в ней распределены особым образом:
- первый 31 символ – управляющие (с 00000000 по 00011111). Служат для служебных команд, вывода на принтер или экран, звуковых сигналов, форматирования текста;
- следующие с 32 по 127 (00100000 – 01111111) латинский алфавит и вспомогательные символы и знаки препинания;
- остальные, до 255-го (10000000 – 11111111) – альтернативная, часть таблицы для специальных задач и отображения национальных алфавитов;
Расшифровка значений в ней показано в таблице.

Если вы считаете, что «0» и «1» расположены в хаотичном порядке, то глубоко ошибаетесь. На примере любого числа я вам покажу закономерность и научу читать цифры, записанные двоичным кодом. Но для этого примем некоторые условности:
- Байт из 8 знаков будем читать справа налево;
- Если в обычных числах у нас используются разряды единиц, десятков, сотен, то здесь (читая в обратном порядке) для каждого бита представлены различные степени «двойки»: 256-124-64-32-16-8- 4-2-1;
- Теперь смотрим на двоичный код числа, например 00011011. Там, где в соответствующей позиции есть сигнал «1» – берем значения этого разряда и суммируем их привычным способом. Соответственно: 0+0+0+32+16+0+2+1 = 51. В правильности данного метода вы можете убедиться, взглянув на таблицу кодов.

Теперь, мои любознательные друзья, вы не только знаете что такое двоичный код, но и умеете преобразовать зашифрованную им информацию.
Язык, понятный современной технике
Конечно, алгоритм считывания двоичного кода процессорными устройствами намного сложнее. Но зато его помощью можно записать все что угодно:
- Текстовую информацию с параметрами форматирования;
- Числа и любые операции с ними;
- Графические и видео изображения;
- Звуки, в том числе и выходящие и за предел нашей слышимости;
Помимо этого, благодаря простоте «изложения» возможны различные способы записи бинарной информации:
Дополняет преимущества двоичного кодирования практически неограниченные возможности по передаче информации на любые расстояния. Именно такой способ связи используется с космическими кораблями и искусственными спутниками.
Так что, сегодня двоичная система счисления является языком, понятным большинству используемых нами электронных устройств. И что самое интересное, никакой другой альтернативы для него пока не предвидится.

Думаю, что изложенной мною информации для начала вам будет вполне достаточно. А дальше, если возникнет такая потребность, каждый сможет углубиться в самостоятельное изучение этой темы.
Я же буду прощаться и после небольшого перерыва подготовлю для вас новую статью моего блога, на какую-нибудь интересную тему.
Лучше, если вы сами ее мне подскажите;)
До скорых встреч.
Термин «бинарный» по смыслу – состоящий из двух частей, компонентов. Таким образом бинарные коды это коды которые состоят только из двух символьных состояний например черный или белый, светлый или темный, проводник или изолятор. Бинарный код в цифровой технике это способ представления данных (чисел, слов и других) в виде комбинации двух знаков, которые можно обозначить как 0 и 1. Знаки или единицы БК называют битами. Одним из обоснований применения БК является простота и надежность накопления информации в каком-либо носителе в виде комбинации всего двух его физических состояний, например в виде изменения или постоянства светового потока при считывании с оптического кодового диска.
Существуют различные возможности кодирования информации.
Двоичный код
В цифровой технике способ представления данных (чисел, слов и других) в виде комбинации двух знаков, которые можно обозначить как 0 и 1. Знаки или единицы ДК называют битами.
Одним из обоснований применения ДК является простота и надежность накопления информации в каком-либо носителе в виде комбинации всего двух его физических состояний, например в виде изменения или постоянства магнитного потока в данной ячейке носителя магнитной записи.
Наибольшее число, которое может быть выражено двоичным кодом, зависит от количества используемых разрядов, т.е. от количества битов в комбинации, выражающей число. Например, для выражения числовых значений от 0 до 7 достаточно иметь 3-разрядный или 3-битовый код:
| числовое значение | двоичный код |
| 0 | 000 |
| 1 | 001 |
| 2 | 010 |
| 3 | 011 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
Отсюда видно, что для числа больше 7 при 3-разрядном коде уже нет кодовых комбинаций из 0 и 1.
Переходя от чисел к физическим величинам, сформулируем вышеприведенное утверждение в более общем виде: наибольшее количество значений m какой-либо величины (температуры, напряжения, тока и др.), которое может быть выражено двоичным кодом, зависит от числа используемых разрядов n как m=2n. Если n=3, как в рассмотренном примере, то получим 8 значений, включая ведущий 0.
Двоичный код является многошаговым кодом. Это означает, что при переходе с одного положения (значения) в другое могут изменятся несколько бит одновременно. Например число 3 в двоичном коде = 011. Число же 4 в двоичном коде = 100. Соответственно при переходе от 3 к 4 меняют свое состояние на противоположное все 3 бита одновременно. Считывание такого кода с кодового диска привело бы к тому, что из-за неизбежных отклонений (толеранцев) при производстве кодового диска изменение информации от каждой из дорожек в отдельности никогда не произойдет одновременно. Это в свою очередь привело бы к тому, что при переходе от одного числа к другому кратковременно будет выдана неверная информация. Так при вышеупомянутом переходе от числа 3 к числу 4 очень вероятна кратковременная выдача числа 7 когда, например, старший бит во время перехода поменял свое значение немного раньше чем остальные. Чтобы избежать этого, применяется так называемый одношаговый код, например так называемый Грей-код.
Код Грея
Грей-код является так называемым одношаговым кодом, т.е. при переходе от одного числа к другому всегда меняется лишь какой-то один из всех бит информации. Погрешность при считывании информации с механического кодового диска при переходе от одного числа к другому приведет лишь к тому, что переход от одного положения к другом будет лишь несколько смещен по времени, однако выдача совершенно неверного значения углового положения при переходе от одного положения к другому полностью исключается.
Преимуществом Грей-кода является также его способность зеркального отображения информации. Так инвертируя старший бит можно простым образом менять направление счета и таким образом подбирать к фактическому (физическому) направлению вращения оси. Изменение направления счета таким образом может легко изменяться управляя так называемым входом ” Complement “. Выдаваемое значение может таким образом быть возврастающим или спадающим при одном и том же физическом направлении вращения оси.
Поскольку информация выраженая в Грей-коде имеет чисто кодированный характер не несущей реальной числовой информации должен он перед дальнейшей обработкой сперва преобразован в стандартный бинарный код. Осуществляется это при помощи преобразователя кода (декодера Грей-Бинар) который к счастью легко реализируется с помощью цепи из логических элементов «исключающее или» (XOR) как програмным так и аппаратным способом.
Соответствие десятичных чисел в диапазоне от 0 до 15 двоичному коду и коду Грея
| Двоичное кодирование | Кодирование по методу Грея |
||||
| Десятичный код |
Двоичное значение | Шестнадц. значение | Десятичный код | Двоичное значение | Шестнадц. значение |
| 0 | 0000 | 0h | 0 | 0000 | 0h |
| 1 | 0001 | 1h | 1 | 0001 | 1h |
| 2 | 0010 | 2h | 3 | 0011 | 3h |
| 3 | 0011 | 3h | 2 | 0010 | 2h |
| 4 | 0100 | 4h | 6 | 0110 | 6h |
| 5 | 0101 | 5h | 7 | 0111 | 7h |
| 6 | 0110 | 6h | 5 | 0101 | 5h |
| 7 | 0111 | 7h | 4 | 0100 | 4h |
| 8 | 1000 | 8h | 12 | 1100 | Ch |
| 9 | 1001 | 9h | 13 | 1101 | Dh |
| 10 | 1010 | Ah | 15 | 1111 | Fh |
| 11 | 1011 | Bh | 14 | 1110 | Eh |
| 12 | 1100 | Ch | 10 | 1010 | Ah |
| 13 | 1101 | Dh | 11 | 1011 | Bh |
| 14 | 1110 | Eh | 9 | 1001 | 9h |
| 15 | 1111 | Fh | 8 | 1000 | 8h |
Преобразование кода Грея в привычный бинарный код можно осуществить используя простую схему с инверторами и логическими элементами “исключающее или” как показано ниже:
Код Gray-Excess
Обычный одношаговый Грей-код подходит для разрешений, которые могут быть представлены в виде числа возведенного в степень 2. В случаях где надо реализовать другие разрешения из обычного Грей-кода вырезается и используется средний его участок. Таким образом сохраняется «одношаговость» кода. Однако числовой диапазон начинается не с нуля, а смещяется на определенное значение. При обработке информации от генерируемого сигнала отнимается половина разницы между первоначальным и редуцированным разрешением. Такие разрешения как например 360? для выражения угла часто реализируются этим методом. Так 9-ти битный Грей-код равный 512 шагов, урезанный с обеих сторон на 76 шагов будет равен 360°.
Разрядность двоичного кода, Преобразование информации из непрерывной формы в дискретную, Универсальность двоичного кодирования, Равномерные и неравномерные коды, Информатика 7 класс Босова, Информатика 7 класс
1.5.1. Преобразование информации из непрерывной формы в дискретную
Для решения своих задач человеку часто приходится преобразовывать имеющуюся информацию из одной формы представления в другую. Например, при чтении вслух происходит преобразование информации из дискретной (текстовой) формы в непрерывную (звук). Во время диктанта на уроке русского языка, наоборот, происходит преобразование информации из непрерывной формы (голос учителя) в дискретную (записи учеников).
Информация, представленная в дискретной форме, значительно проще для передачи, хранения или автоматической обработки. Поэтому в компьютерной технике большое внимание уделяется методам преобразования информации из непрерывной формы в дискретную.
Дискретизация информации - процесс преобразования информации из непрерывной формы представления в дискретную.
Рассмотрим суть процесса дискретизации информации на примере.
На метеорологических станциях имеются самопишущие приборы для непрерывной записи атмосферного давления . Результатом их работы являются барограммы - кривые, показывающие, как изменялось давление в течение длительных промежутков времени. Одна из таких кривых, вычерченная прибором в течение семи часов проведения наблюдений, показана на рис. 1.9.
На основании полученной информации можно построить таблицу, содержащую показания прибора в начале измерений и на конец каждого часа наблюдений (рис. 1.10).
Полученная таблица даёт не совсем полную картину того, как изменялось давление за время наблюдений: например, не указано самое большое значение давления, имевшее место в течение четвёртого часа наблюдений. Но если занести в таблицу значения давления, наблюдаемые каждые полчаса или 15 минут, то новая таблица будет давать более полное представление о том, как изменялось давление.
Таким образом, информацию, представленную в непрерывной форме (барограмму, кривую), мы с некоторой потерей точности преобразовали в дискретную форму (таблицу).
В дальнейшем вы познакомитесь со способами дискретного представления звуковой и графической информации.
Цепочки из трёх двоичных символов получаются дополнением двухразрядных двоичных кодов справа символом 0 или 1. В итоге кодовых комбинаций из трёх двоичных символов получается 8 - вдвое больше, чем из двух двоичных символов:
Соответственно, четырёхразрядйый двоичный позволяет получить 16 кодовых комбинаций, пятиразрядный - 32, шестиразрядный - 64 и т. д. Длину двоичной цепочки - количество символов в двоичном коде - называют разрядностью двоичного кода.
Обратите внимание, что:
4 = 2 * 2,
8 = 2 * 2 * 2,
16 = 2 * 2 * 2 * 2,
32 = 2 * 2 * 2 * 2 * 2 и т. д.
Здесь количество кодовых комбинаций представляет собой произведение некоторого количества одинаковых множителей, равного разрядности двоичного кода.
Если количество кодовых комбинаций обозначить буквой N, а разрядность двоичного кода - буквой i, то выявленная закономерность в общем виде будет записана так:
N = 2 * 2 * ... * 2.
i множителей
В математике такие произведения записывают в виде:
N = 2 i .
Запись 2 i читают так: «2 в i-й степени».
Задача. Вождь племени Мульти поручил своему министру разработать двоичный и перевести в него всю важную информацию . Двоичный какой разрядности потребуется, если алфавит, используемый племенем Мульти, содержит 16 символов? Выпишите все кодовые комбинации.
Решение. Так как алфавит племени Мульти состоит из 16 символов, то и кодовых комбинаций им нужно 16. В этом случае длина (разрядность) двоичного кода определяется из соотношения: 16 = 2 i . Отсюда i = 4.
Чтобы выписать все кодовые комбинации из четырёх 0 и 1, воспользуемся схемой на рис. 1.13: 0000, 0001, 0010, 0011, 0100, 0101, 0110,0111,1000,1001,1010,1011,1100,1101,1110,1111.
1.5.3. Универсальность двоичного кодирования
В начале этого параграфа вы узнали, что, представленная в непрерывной форме, может быть выражена с помощью символов некоторого естественного или формального языка. В свою очередь, символы произвольного алфавита могут быть преобразованы в двоичный. Таким образом, с помощью двоичного кода может быть представлена любая на естественных и формальных языках, а также изображения и звуки (рис. 1.14). Это и означает универсальность двоичного кодирования.
Двоичные коды широко используются в компьютерной технике, требуя только двух состояний электронной схемы - «включено» (это соответствует цифре 1) и «выключено» (это соответствует цифре 0).
Простота технической реализации - главное достоинство двоичного кодирования. Недостаток двоичного кодирования - большая длина получаемого кода.
1.5.4. Равномерные и неравномерные коды
Различают равномерные и неравномерные коды. Равномерные коды в кодовых комбинациях содержат одинаковое число символов, неравномерные - разное.
Выше мы рассмотрели равномерные двоичные коды.
Примером неравномерного кода может служить азбука Морзе, в которой для каждой буквы и цифры определена последовательность коротких и длинных сигналов. Так, букве Е соответствует короткий сигнал («точка»), а букве Ш - четыре длинных сигнала (четыре «тире»). Неравномерное позволяет повысить скорость передачи сообщений за счёт того, что наиболее часто встречающиеся в передаваемой информации символы имеют самые короткие кодовые комбинации.
Информация, которую дает этот символ, равна энтропии системы и максимальна в случае, когда оба состояния равновероятны; в этом случае элементарный символ передает информацию 1 (дв. ед.). Поэтому основой оптимального кодирования будет требование, чтобы элементарные символы в закодированном тексте встречались в среднем одинаково часто.
Изложим здесь способ построения кода, удовлетворяющего поставленному условию; этот способ известен под названием «кода Шеннона - Фэно». Идея его состоит в том, что кодируемые символы (буквы или комбинации букв) разделяются на две приблизительно равновероятные группы: для первой группы символов на первом месте комбинации ставится 0 (первый знак двоичного числа, изображающего символ); для второй группы - 1. Далее каждая группа снова делится на две приблизительно равновероятные подгруппы; для символов первой подгруппы на втором месте ставится нуль; для второй подгруппы - единица и т. д.
Продемонстрируем принцип построения кода Шеннона - Фэно на материале русского алфавита (табл. 18.8.1). Отсчитаем первые шесть букв (от «-» до «т»); суммируя их вероятности (частоты), получим 0,498; на все остальные буквы (от «н» до «сф») придется приблизительно такая же вероятность 0,502. Первые шесть букв (от «-» до «т») будут иметь на первом месте двоичный знак 0. Остальные буквы (от «н» до «ф») будут иметь на первом месте единицу. Далее снова разделим первую группу на две приблизительно равновероятные подгруппы: от «-» до «о» и от «е» до «т»; для всех букв первой подгруппы на втором месте поставим нуль, а второй подгруппы"- единицу. Процесс будем продолжать до тех пор, пока в каждом подразделении не останется ровно одна буква, которая и будет закодирована определенным двоичным числом. Механизм построения кода показан на таблице 18.8.2, а сам код приведен в таблице 18.8.3.
Таблица 18.8.2.
|
Двоичные знаки |
|||||||||
Таблица 18.8.3
С помощью таблицы 18.8.3 можно закодировать и декодировать любое сообщение.
В виде примера запишем двоичным кодом фразу: «теория информации»
01110100001101000110110110000
0110100011111111100110100
1100001011111110101100110
Заметим, что здесь нет необходимости отделять друг от друга буквы специальным знаком, так как и без этого декодирование выполняется однозначно. В этом можно убедиться, декодируя с помощью таблицы 18.8.2 следующую фразу:
10011100110011001001111010000
1011100111001001101010000110101
010110000110110110
(«способ кодирования»).
Однако необходимо отметить, что любая ошибка при кодировании (случайное перепутывание знаков 0 и 1) при таком коде губительна, так как декодирование всего следующего за ошибкой текста становится невозможным. Поэтому данный принцип кодирования может быть рекомендован только в случае, когда ошибки при кодировании и передаче сообщения практически исключены.
Возникает естественный вопрос: а является ли составленный нами код при отсутствии ошибок действительно оптимальным? Для того чтобы ответить на этот вопрос, найдем среднюю информацию, приходящуюся на один элементарный символ (0 или 1), и сравним ее с максимально возможной информацией, которая равна одной двоичной единице. Для этого найдем сначала среднюю информацию, содержащуюся в одной букве передаваемого текста, т. е. энтропию на одну букву:
 ,
,
где - вероятность того, что буква примет определенное состояние («-», о, е, а,…, ф).
Из табл. 18.8.1 имеем
(дв. единиц на букву текста).
По таблице 18.8.2 определяем среднее число элементарных символов на букву
Деля энтропию на, получаем информацию на один элементарный символ
![]() (дв.
ед.).
(дв.
ед.).
Таким образом, информация на один символ весьма близка к своему верхнему пределу 1, а выбранный нами код весьма близок к оптимальному. Оставаясь в пределах задачи кодирования по буквам, мы ничего лучшего получить не сможем.
Заметим, что в случае кодирования просто двоичных номеров букв мы имели бы изображение каждой буквы пятью двоичными знаками и информация на один символ была бы
![]() (дв.
ед.),
(дв.
ед.),
т. е. заметно меньше, чем при оптимальном буквенном кодировании.
Однако надо заметить, что кодирование «по буквам» вообще не является экономичным. Дело в том, что между соседними буквами любого осмысленного текста всегда имеется зависимость. Например, после гласной буквы в русском языке не может стоять «ъ» или «ь»; после шипящих не могут стоять «я» или «ю»; после нескольких согласных подряд увеличивается вероятность гласной и т. д.
Мы знаем, что при объединении зависимых систем суммарная энтропия меньше суммы энтропий отдельных систем; следовательно, информация, передаваемая отрезком связного текста, всегда меньше, чем информация на один символ, умноженная на число символов. С учетом этого обстоятельства более экономный код можно построить, если кодировать не каждую букву в отдельности, а целые «блоки» из букв. Например, в русском тексте имеет смысл кодировать целиком некоторые часто встречающиеся комбинации букв, как «тся», «ает», «ние» и т. п. Кодируемые блоки располагаются в порядке убывания частот, как буквы в табл. 18.8.1, а двоичное кодирование осуществляется по тому же принципу.
В ряде случаев оказывается разумным кодировать даже не блоки из букв, а целые осмысленные куски текста. Например, для разгрузки телеграфа в предпраздничные дни целесообразно кодировать условными номерами целые стандартные тексты, вроде:
«поздравляю новым годом желаю здоровья успехов работе».
Не останавливаясь специально на методах кодирования блоками, ограничимся тем, что сформулируем относящуюся сюда теорему Шеннона.
Пусть имеется источник информации и приемник, связанные каналом связи (рис. 18.8.1).
![]()
Известна производительность источника информации, т. е. среднее количество двоичных единиц информации, поступающее от источника в единицу времени (численно оно равно средней энтропии сообщения, производимого источникам в единицу времени). Пусть, кроме того, известна пропускная способность канала, т. е. максимальное количество информации (например, двоичных знаков 0 или 1), которое способен передать канал в ту же единицу времени. Возникает вопрос: какова должна быть пропускная способность канала, чтобы он «справлялся» со своей задачей, т. е. чтобы информация от источника к приемнику поступала без задержки?
Ответ на этот вопрос дает первая теорема Шеннона. Сформулируем ее здесь без доказательства.
1-я теорема Шеннона
Если пропускная способность канала связи больше энтропии источника информации в единицу времени
то всегда можно закодировать достаточно длинное сообщение так, чтобы оно передавалось каналом связи без задержки. Если же, напротив,
то передача информации без задержек невозможна.
Расшифровка бинарного кода применяется для перевода с машинного языка на обычный. Онлайн инструменты работают быстро, хотя и вручную это сделать несложно.
Бинарный или двоичный код используется для передачи информации в цифровом виде. Набор из всего лишь двух символов, например 1 и 0, позволяет зашифровать любую информацию, будь то текст, цифры или изображение.
Как шифровать бинарным кодом
Для ручного перевода в бинарный код любых символов используются таблицы, в которых каждому символу присвоен двоичный код в виде нулей и единиц. Наиболее распространенной системой кодировки является ASCII, в которой применяется 8-ми битная запись кода.
В базовой таблице приведены бинарные коды для латинской азбуки, цифр и некоторых символов.
В расширенную таблицу добавлена бинарная интерпретация кириллицы и дополнительных знаков.
Для перевода из двоичного кода в текст или цифры достаточно выбирать нужные коды из таблиц. Но, естественно, вручную такую работу выполнять долго. И ошибки, к тому же, неизбежны. Компьютер справляется с расшифровкой куда быстрее. И мы даже не задумываемся, набирая на экране текст, что в это момент производится перевод текста в бинарный код.
Перевод бинарного числа в десятичное
Для ручного перевода числа из бинарной системы счисления в десятичную можно использовать довольно простой алгоритм:
- Ниже бинарного числа, начиная с крайней правой цифры, написать цифру 2 в возрастающих степенях.
- Степени числа 2 умножить на соответствующую цифру бинарного числа (1 или 0).
- Получившиеся значения сложить.
Вот как этот алгоритм выглядит на бумаге:

Онлайн сервисы для бинарной расшифровки
Если все же требуется увидеть расшифрованный бинарный код, либо, наоборот, перевести текст в двоичную форму, проще всего использовать онлайн-сервисы, предназначенные для этих целей.
Два окна, привычных для онлайн-переводов позволяют практически одновременно увидеть оба варианта текста в обычной и бинарной форме. И расшифровка осуществляется в обе стороны. Ввод текста производится простым копированием и вставкой.